

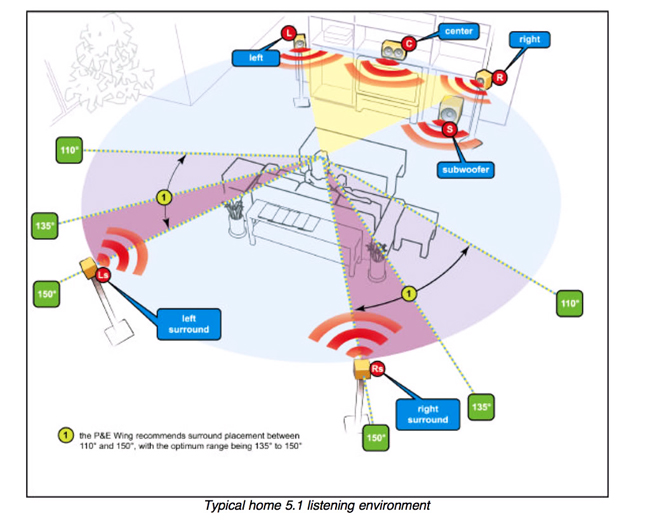
Surround Sound Mixing

Introduction
Numerous opportunities exist today for up-and-coming audio engineers in the post- production industry, especially with the need to satisfy a cinema theatre audience, as well as consumers possessing a high-quality home theatre system. There has recently been an increase in new post-production studios, especially facilities that are aiming to capitalize on productions with medium priced budgets. With more facilities being launched, the need for multi-talented engineers is sure to escalate in the near future. In this article I will discuss in detail the comprehension, methodology and utilization of surround sound mixing as it primarily pertains to music. I trust this explanation will be beneficial for engineers desiring to enter the field of post-production surround sound mixing.
Historical Perspective
Surround sound mixing has surely evolved since Disneys release of Fantasia (1940); the first surround sound movie ever produced (Fantasound).
Not only has the viewing experience in large cinemas improved impressively over the last 20 years, consumers may now enjoy a fantastic entertaining experience with an affordable home theatre system that features a large viewing screen with a superb surround sound audio system.
The increase in demand for a home theater system is to a certain degree decreasing the desire for consumers to venture out to a theatre to watch the newest film releases.
Major film companies are now often spending between $100 million to $250 million to produce potential Blockbuster hit movies. However these big budget movies are not always translating into financial success. Theres been an implosion where three or four or maybe even a half-dozen mega-budget movies are going to go crashing into the ground, and thats going to change the paradigm, states Oscar winning director Steven Spielberg.
Recent movies like The Lone Ranger, which cost Disney over $300 million to produce and market, has taken in just $147 million worldwide, roughly half of which goes to theater owners. Alternatively there has been a nice surge in low priced films doubling and tripling their initial investment just in the theater release alone.
Film and Pay-per-View companies have started to simultaneously release shows for theatre, cable TV, laptops (smartphones) and DVD-Blue Ray, which has prompted major theatre chains and distributors to be concerned about what is sure to be a potential decline in revenues. I am sure that the initial price of a new DVD-Blue Ray release will continue to drop in price, along with the convenient option of downloading a movie which will encourage viewers to wait until a product/download release, rather than standing in the theater admission line of a movie premiere.
Recently music companies have started releasing back catalogues of famous recordings in surround sound for the car surround sound audio system. The ability to offer a dynamic enveloping aural experience for the automobile is becoming very affordable and desirable. The driver is in total control of setting the volume of the individual channels completely offering a maximum surround sound experience. Several studios in California are now specializing for this potential demand in the near future. I believe it will also be only a matter of time for radio stations to start broadcasting live concerts in surround sound for the car and home. CBC-TV and other cable/TV stations are already offering surround sound programming and more networks with more shows are sure to come online.
And now there is streaming!
Laptops, Ipads, and even smart phones are also beginning to take revenue away from the large theatre business. Several TV networks and cable providers are now selling TV series and movies as downloads for a demographic that are especially comfortable paying additional fees to access high quality content. Young people are now viewing more shows and music videos on their laptops and smartphones, with Youtube now the leading source for free video/music. Most listening is done with high quality headphones and listeners will continue to desire excellent sound, which has been verified by the astonishing sales of Beats headphone products and other listening devices from various top quality manufacturers.
Even though the audio is stereo on many of the shows, the stereo sound the listener is hearing is at times, an offshoot of the original surround sound mix. Most engineers will make certain the quality of the surround sound mix is the top notch and also make certain that the subsequent stereo mix is also high quality.
A recurring comment I hear from young people with laptops is that the quality of the story is a leading factor for their choice in viewing content. For them, if a show features a captivating story, the importance of the quality of video and audio playback will never supersede the importance of the storyline. The recent success of the TV series Breaking Bad clearly demonstrates and verifies this conclusion. A lot of these hit series are released on DVD/Blue-Ray or downloaded and often viewed on laptops with headphones. This might be construed as a concern for the engineer whose priority is creating excellent sound, but the conclusion to be taken is that the consumer is primarily concerned with the quality of the storyline. With this demographic feedback, film and TV producers are becoming further convinced that a great storyline does not require a huge budget to produce. Therefore more possibilities will be undertaken with the creation of more shows, which means extra work for the post-production engineer.
Premium cable channels like HBO, Showtime, Disney and AMC are now offering TV productions for a regular monthly service. This market is proving to be highly profitable and will continue to increase in the future.
With Internet-based content becoming more commonplace, the media company Netflix has introduced streaming, with the concept of viewing content without necessarily having access to a TV/cable network, where subscribers can choose from a database that is instantly accessible via the Internet. Netflix is allowing content that is not linked to cable TV providers and is simply using the Internet. They are growing rapidly, recently passing 38 million subscribers who pay the single-user monthly fee of $7.99. For the first time in TV history, Netflix, an Internet based company has received 14 Emmy Nominations (2013). With this type of recognition, Netflix is sure to be perceived as a serious financial threat by major networks and cable TV conglomerates. Then there is Apple TV, Amazon and many other ventures that are sure to arrive on the scene.
What is of interest here is that a good number of these shows are now mixed and broadcast in surround sound. What are exceptionally exciting are the sports networks live broadcasts, which literally attempt to seat you at the actual sports event. I viewed an NHL hockey game where the excitement of a crowd roar could be heard like I was actually sitting in the arena, where I could detect cheers and applause located all around me.
With low cost subscription rates and access to high bandwidth Internet, most industry executives believe that the market will grow for back catalogues to be visually enhanced and remixed in surround sound. If this business strategy proves profitable, which I believe it will, look for an additional motive for an increase in consumer demand for quality home theatre systems.
For up-and-coming audio engineers who would like to get into post-production, the timing could not be any better than now. While the revenues of the music industry are steadily declining, the opposite is happening in the visual media and video game industries. What now qualifies, as popular visual media are; movies, documentaries, TV series and sports entertainment. Major music recording studios are declining in numbers while many new audio post-production facilities are being built at a substantial rate.
The days of requiring millions of dollars for starting up a new audio post-production facility are unwarranted, where today the entrepreneurial engineers financial needs for starting a facility is within financial reason.
Al Omerod, winner of four Geminis, left Deluxe Film Studios in 2006 in Toronto to open his own production facility, Post City Sound, a venture, which satisfies most of his boutique clients, needs for a fraction of the costs of a major audio post-production facility. Post City Sound is only one of the many newer smaller post-production facilities that are proving profitable in the expanding market for medium budget productions. The larger facilities such as Technicolor and Deluxe Film House are simply too expensive for smaller yet numerous film/TV production companies.
With the economy looking positive in the next few years, I believe that home theatre systems will dominate the consumers home electronic purchases. If we take Rogers Cable TV as an example, consumers need only purchase a home theatre system, and be able to download movies, in order for them to have all the flexibility of a DVD, except for the ownership of the hard product of the content. Teenagers, who represent a large purchasing demographic for the entertainment industry will be lured to this new model of supplying exciting entertainment, not as a hard product but as a streaming service that can be purchased for a monthly fee from their local cable TV or an Internet based company like Netflix. If this becomes the model, then the demand for consistent, high- quality entertainment will increase even more once bandwidth is increased and the industry is suitably monetized. When this occurs, more medium-sized production facilities will employ more talented individuals who plan careers in the audio post- production industry. Executive producers will no longer be burdened by the expensive technical services and production costs for films/TV from high-priced facilities, when they can attain 90% of the production quality at a substantial reduction in costs from medium priced post-production facility. The reality of the 10% loss of quality by using a medium priced facility rather than an expensive facility cannot be detected by over 90% of the preferred clientele. The small number of viewers that can detect the 10% drop in quality can only do so in a large cinema setting. Research has also demonstrated that the slight drop in quality can be scarcely detected on a high quality home theater system.
The film/TV industry is also experiencing a developing trend where clients go to smaller independent music facilities for music mixing and end up having the facility complete all of their post-production including final mixing. These smaller facilities are accomplishing this work by utilizing affordable software such as Logic/Final Cut/AVID/Pro-Tools systems.
Will this be the end to quality filmmaking and TV production? I believe it will not! With technology like Final Cut Pro, AVID, HDTV creating excellent productions for Home Theatre playback systems, films will nevertheless look and sound exceptional in the comfort of ones own home. Lets face the undeniable fact that digital downloading is deeply affecting the purchasing habits of the average music listener. Never has so much music been accessible for an affordable price. In typical listening situations, the consumer cannot tell the difference in audio quality between an Apple-ITunes download and a wave file, nor are they concerned, as long as its a good song. It is the quality of the content that is more essential to them than the quality of the audio, which is also why the buying public is mainly interested in purchasing just singles. The preference now of the consumer is to pay $1 for a song instead of paying $15-$20 for an entire album that might have only two or three good songs.
Consider the DVD/Blue Ray. There has been an incredible resurrection of older movies, where nostalgic libraries are being upgraded with improved colour correction and enhanced audio. Do these films look and sound spectacular? Not really, for it does not really matter to the average consumer? Most people will always prefer a superior storyline and excellent music above technical quality. Box office receipts have declined in the last few years and I believe this is due to the lack of good content in films no matter how amazing the film looks and sounds in a large theatre. Of course there will still be blockbuster hits where the visual effects are stunning and the sound very dynamic, but these hit movies will be fewer and far between. By now some of the film companies that produce these blockbuster are losing potential income to consumers who desire to watch and listen to good content in the comfort of their own homes.
In reviewing the qualifications of good story content, test yourself and watch and listen to a movie produced over 30 years ago, such as The Godfather or Lawrence Of Arabia, compared to the recent release of Iron Man 3 or The Lone Ranger. The individual scenes of the classics lasted as long as 20-30 seconds, where the movies today, have on average an edit every 4-6 seconds. These movies featured actors who could truly perform, where cinematographers relied more on visual imagination, and the composers had to score music with full orchestras for longer scenes that needed to embrace the emotional interest of the audience. The acclaimed director Martin Scorcese recently listed his all time favourite 10 movies, and it was interesting to note that all the movies he chose were all made before 1968. Even pay TV shows are reverting back to an era where excellent writing and superb acting are being showcased. Recent Neilson ratings clearly demonstrate and confirm this new reality and executive approach with the recent remarkable success of shows like House Of Cards, Breaking Bad and Boardwalk.
With this new innovative business strategy, we should see further growth in the cinema film, internet and pay-per-view TV industry, where quality content will require consistent excellence along with the need for numerous choices in the various genres of productions. With the increase in Internet bandwidth, larger high-resolution picture and quality surround sound, the demand for first-class visuals and outstanding audio will be indispensible in engaging and retaining the consumers interest.
The consumer is becoming more accustomed to enjoying their entertainment in a comfortable home environment, be it through head phones with a laptop or viewing a large LCD screen with surround sound. Members of a family can now watch shows at various times and use the pause button for kitchen and bathroom breaks and not be forced to pay extravagant prices for confectionary items that they would normally pay at a theater. Theatre chains have tried to keep attendance elevated with improved quality seating, superior sound and alcohol services, but this costly upgrade of services is affecting their financial bottom line. Watching a movie in a large theater is very entertaining but also has its shortcomings; I personally loathe the sound of people continually chatting, eating chips, blocking my view, stepping on my toes and not getting the snacks I want. Some people say this is a trivial concern, but from my experience, watching and listening to Superman and Batman were just as pleasurable on a superb home theatre system than in the theater, where lining up for an hour in January is not my idea of relaxation and entertainment. The idea of spending $4,500 on a home theatre system with a 52-inch TV screen seems like a wise long-term investment to me.
The key argument here is; do home theatre systems that are becoming more inexpensive and enhanced for the average consumer, out weigh the advantages of going out to a movie theater anymore.
Is it better to wait a few weeks after the premier and watch the movie at home? Some may argue this point, but the fact is, the trend is starting to favour more home theater systems.
Video Game Industry
The most successful financial contributor of the entertainment industry is now the video game market, surpassing the movie and music industry combined. In 2011, the global video game market was valued at US$65 billion. The Video Game industrys is rapidly establishing itself as the single most exciting and vigorous creative industry around: a sector able to claim not only booming revenues and growing audiences, but a multitude of talents and new ideas that is increasingly attracting some of the foremost influential figures in film, television, music and the other arts. The release of the game Call Of Duty: Black Ops took in an astounding $650 million in its first five days alone. Recent studies show that 67% of all homes in the USA now have a video game system and that females make up a surprising 40% of the participants. Games like Nintendos Wii, Sonys PlayStation and Microsofts Xbox are now becoming standard household items in the home of almost every teenager. Sonys PlayStation 2 has sold over a record 165 million units alone. Most of the recent versions of these games can now play Blue Rays, HD-DVDs and offer 3D graphics.
Canada is presently one of the key leading game developers and publishers in the industry with major corporations such as Ubisoft in Montreal and Electronic Arts in Vancouver. With the Quebec government offering generous financial subsidies for the industry, Montreal has recently confirmed that over 2,000 people are now directly employed in the Video Game industry. Ubisoft a Global player whos largest development studio is in Montreal, has recently opened an additional office in Toronto where they are focused on developing Tom Clancys hit Splinter Cell 6.
With this movement and surge in the Video Game industry there will be an enormous and escalating need for audio designers and audio engineers. These engineers will have to be very knowledgeable and proficient in surround sound mixing.
Concert TV
Concerttv.com is an innovative cable station totally dedicated to broadcasting music concerts that have been pre-recorded, edited and mixed. The original recording is recorded with close mics and ambient mics and remixed for surround sound listening. This specialty channel now offers all types of genres and already possesses a hefty back catalogue of shows ready to be remixed for surround sound. The newer shows are mixed with the vocals and musicians panned across the front channels with the rear channels dedicated for the ambience of the environment with associated crowd responses.
More cable TV providers are getting into the action and this format presents an additional opportunity for up and coming engineers desiring careers in music mixing for surround sound.
So what has this all got to do with mastering surround-sound mixing?
As previously stated, the demand for large costly production facilities needed to achieve a fantastic sounding mix has decreased in the last five years and is likely to lose market share to smaller production facilities. The smaller facilities are decently priced and posses similar professional standards. This allows the up-and-coming engineers more employment opportunities in the expanding growth of medium priced audio post- production facilities. These engineers are now better positioned to demonstrate their creative talents and potential and even launch their own business ventures.
I know of a talented young mixer at small post facility in Toronto, who recently is mixing three shows per week for TV and who has recently engineered with me on large surround sound film projects. All of this work was done on a Control 24, Pro Tools HD, Waves plug-ins, Final Cut Pro, 42 LCD monitor, with a Tannoy surround sound monitor system. Recent graduates of Audio Post Production schools have consistently demonstrated their abilities to combine numerous technical skills with intrinsic creativity to meet the future demands of the audio post-production industry. How are they achieving this? Through continuous monitoring of the future needs of the industry in order to stay well informed of the innovative trends that will fuel the increasing demands of consumer entertainment.
The wider latitudes and options in surround sound mixing are opportune incentives for the mixing engineer to be more creative and inspired in elevating audio to higher standards that will have greater appeal for the consumer. When approaching a 5.1 surround sound project, I personally try to envision the sound of the final product before I even begin mixing, an approach that has worked well for me in the past when mixing in the stereo format. I always ask myself how should I record audio knowing that I will have a surround sound template to fill? What signal processing and effects will I need to employ? What will be the focus in the mix, and how can I ensure the quality of the surround-sound mix for the cinema to be as enjoyable for the consumers home theatre system? In this article I am going to explore surround sound recording and mixing with; 1) analysis of conventional methodology, 2) endorse my own personal concepts and recommendations, which will solely be a subjective perspective based on how I deal with surround sound and it will at times differ radically from conventional opinions and standardized procedure.
How We Localize Sound (Duplex Theory)
If one is to maximize the effects of localizing audio in surround sound mixing, one must first investigate how humans perceive localization of a sound source. Listening to a sound source and verifying its location is determined by the position of the head relative to the sound source (the Direct Path). When the sound arrives to both ears, the time, frequency content, and amplitude will be different between the left and right ears.
It is important to confirm that a sounds frequency content lessens over distance, particularly the higher frequencies, due to atmospheric conditions.
A sound will reach the ipsilateral ear (the ear closest to the sound source) prior to reaching the contralateral ear (the ear farthest from the sound source). The difference between the onset of non-continuous (transient) sounds or phase of more continuous sounds at both ears is known as the interaural time delay (ITD).
Similarly, given that the head separates the ears, when the wavelengths of a sound are short relative to the size of the head, the head will act as an acoustic shadow, attenuating the sound pressure level of the waves reaching the contralateral ear. This difference in level between the waves reaching the ipsilateral and contralateral ears is known as the interaural level difference (ILD).
When the sound source lies on the median plane (center), the distance from the sound source to the left and right ear will be identical; thus the sound will reach both ears at the same time. In addition, the sound pressure level of the sound at each ear will also be identical. As a result, both the ITD and ILD differences will be zero. As the source moves to the right or left, ITD and ILD cues will increase until the source is directly to the right or left of the listener respectively, where the ITD and ILD will cease to be as influential in localizing a sound source. (e.g. ±90 degrees azimuth).
Similarly, when the sound source is centered directly behind the listener, both ITD and ILD will be zero, and as the sound moves to the right or left, ITD and ILD cues will increase until the sound source is directly facing the left or right of the listener, where the ITD and ILD will cease to be as influential in localizing a sound source. (e.g. ±90 degrees azimuth).
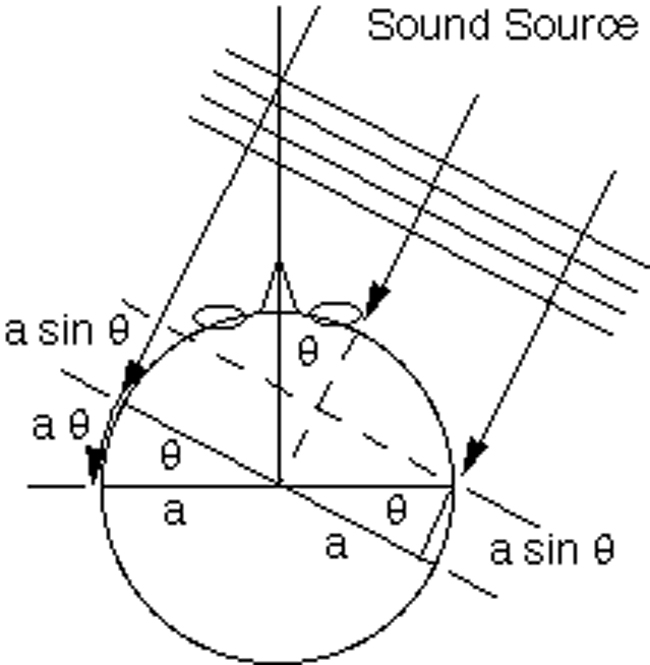
Figure 1: (Duplex Theory) Localization of a sound source. ITD and ILD
Separation of ITD (time) and ILD (level) Cues
Although this Duplex Theory incorporates both ITD and ILD cues in localization of sound, the cues do not necessarily operate together. ITDs are prevalent primarily for frequencies lower than 1500Hz, where the wavelength of the arriving sound is long relative to the diameter of the head and where the phase of the sound reaching the ears can be clearly determined for localization. For wavelengths smaller than the diameter of the head, the difference in distance is greater than one wavelength, leading to an unclear condition, where the difference does not contribute to localization of the sound source. In this situation, it is possible to have many frequencies above 1500 Hz arriving in phase to the ears (e.g., the frequency 1500Hz can also be in phase with 3kHz, 6kHz and 12kHz for both ears). This will cause inaccurate localization.
For low frequency sounds in which the ITD cues are prevalent and the waves are greater than the diameter of the head, the sound waves experience diffraction, whereby they are not blocked by the head, but rather bend around the head to reach the contralateral ear (omnidirectional) for localization purposes.
As a result, ILD cues for low frequency sounds will be as large as 5dB. However, for frequencies greater than 1500 Hz, where the wavelengths are smaller than the head, the wavelengths are too small to bend around the head and are therefore blocked by it (e.g., shadowed by the head). As a result, a decrease in the energy of the sound reaching the contralateral ear will create an ILD location cue. (See Fig. 1) To conclude, identification of a sound source is determined by the difference in time and phase relationship, as well as amplitude.
In Figure 1, we see that early part of the phase of the signal will arrive at the right ear before the left ear (ITD). The level of the signal will be louder in the right ear than the left, and the mid- high frequency content of the original signal will only arrive at the right ear.
Precedence Effect (Hass Effect)
The auditory system of the ear can clearly localize a sound source in the presence of multiple reflections and reverberation. In fact, the auditory system combines both direct and reflected sounds in such a way that they are heard as a localized event and the localization of the direct sound has been determined by the precedence effect, also known as the Haas effect or the law of first waveforms. The precedence effect allows us to localize a sound source in the presence of reverberation, even when the amplitude of the reverberation is greater than the direct sound. Localization is based on the time difference between the left and right ear of the arriving sound event. (Figure 2) Of the various experiments that investigate the precedence effect, the most common exercise positions a to have a listener in front and between two loudspeakers placed in a triangular setting, in an anechoic or a very dead sounding environment.
One loudspeaker is used to deliver the direct sound while the other loudspeaker delivers a delayed replicate of the direct sound, thus simulating a slight delay. Such studies indicate the following: 1) If a direct sound event is generated simultaneously with identical amplitude in both the left and right loudspeakers, then a single sound source (virtual source) will be perceived by the listener at a location point centered exactly between the left and right loudspeakers. (Phantom center mono position) 2) When the direct sound and the delayed sound are of equal volume but the delayed sound one is increased from 0.1msec to 1 msec in the right loudspeaker, the perceived location of the sound source starts to move towards the left sound loudspeaker (direct) and this is known as summing localization.
3) When a delay between 1msec and approx. 15msec of the original sound is delivered form the right loudspeaker, the sound source is perceived as directly coming from the left loudspeaker even though the volume levels are identical between the left and right loudspeakers 4) When the delay in the right loudspeaker exceeds 15msec, the direct sound is precisely localized in the left loudspeaker; however and delayed sound (right loudspeaker) is also now localized as a distinct sound and is perceived as an early reflection of the direct sound creating a sense of distance and ambience.
5) If the sound source in the right loudspeaker is delayed between 1msec-15msec from the from the same sound source of the left loudspeaker and is louder in amplitude (+3db to +6db), the listener will perceive the sound as coming from the left loudspeaker even though the right loudspeaker is louder in amplitude. The slight difference in milliseconds (1msec-15msec) of an identical sound arriving from both loudspeakers overrides the difference in amplitude between both loudspeakers and will appear to be discretely localized in the non-delay speaker.
The experiments show how we are capable of correctly localizing a sound source in the presence of reverberation, provided the reflection arrives within 15msec of the direct sound. The possibilities for using the precedence effect in widening the image of the dedicated center speaker for surround sound mixing will be explored and experimented later in the article.
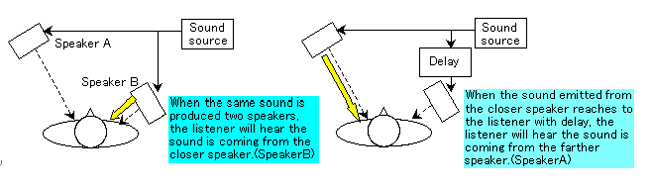
Figure 2: The Precedence Effect (Haas Effect)
Direct Path (Original) Sound
If you were to suspend two individuals ten meters above the ground and three meters apart from each other in an open field, you would be able to set up a situation where they could have a conversation with each other where the only audio heard is via the direct path route.
There would be no floor, ceiling, or walls to reflect the original signal, where each of the two individuals would describe the audio characteristics as being totally dry sounding without the ambience one would hear in an enclosed environment. When the distance between the two individuals increases, the amplitude and frequency response would decrease, due to the inverse law of sound and the absorptive atmospheric conditions.
When one individuals is talking directly on axis to one ear of an individual just listening, the high frequency content of the signal would sound very clear and subjectively described by the listener as emotionally intimate.
Later in the article, I will present a detailed explanation on creating a dimensional effect to achieve an emotional intimate effect between the lead vocalist and the listener.
In an enclosed environment the direct path sound is always the loudest portion of the overall audio experience, where early reflections and reverb are always lesser in amplitude. The only exception is if the direct path between the sound source and the listener would be obstructed.
In an enclosed environment like a performance center, the listener will always look on axis at the sound source; therefore the image of the performer is heard as being dead center no matter what the acoustics of environment are.
First and Early Reflections
Sound radiating from surfaces in an enclosed reflective environment are known as early reflections (e.g., walls, floor, and ceiling). These reflections contribute to enhancing a sense of dimension in an enclosed reflective environment. Highly sophisticated mathematics and physics are used by studio designers, in their efforts to build excellent sounding recording studios, mixing rooms and live concert venues. (Figure 3) Early reflections typically arrive very soon after the arrival of the direct sound but are lesser in amplitude and frequency content. The length of time difference between the arrival of the direct sound and the arrival of the early reflections will connect to an amplitude decrease, with amplitude decreasing as the difference in time lengthens.
Effective sounding reflections that enhance a listening experience need to arrive to the ear within 15msec-80msec of the arrival time of the direct path and must sound lower in amplitude with less high frequency content. The length of time between the direct sound and the early reflections influence the amplitude and high frequency content of the reflections, with amplitude and high frequency content decreasing over time. Therefore the distance of the reflective surfaces from the listening position effect their amplitude and high frequency content. Reflections arriving to the listener between 15msec (left) and 30msec (right) will be louder and contain more high frequency content than reflections arriving between 60msec (left) and 80msec (right). Left and right early reflections arriving less than 15msec between each other could produce a flanging effect and/or image location difficulties of the original sound source. This effect can be easily produced if one claps their hands and listens for a flutter echo flange within the sound of the echo-delay, an effect caused by 2 or more reflections arriving less than 15msec apart from each other in an enclosed environment with parallel walls. Once the first and early reflections pass the 80msec mark (approx.), they begin to sound detached and discrete from the direct path signal and no longer contribute in influencing a sense of distance and dimension in the overall sound experience. If the sound source is transient sounding in nature, the early reflections are easier to hear and distinguish from each other but might prove to be distracting in a listening experience. Later we will look at how first and early reflections can perform a role in creating a sense of distance and dimension in surround sound mixing. Early reflections continue to multiply over time until there are so many of them they will eventually be perceived as reverb.
Early reflections result from the room surfaces (e.g. walls, floor and ceiling) and are known as the early reflections. They typically arrive very soon after the arrival of the direct sound but are lesser in amplitude and frequency content.
The length of time difference between the arrival of the direct sound and the arrival of the early reflections will connect to an amplitude decrease, with amplitude decreasing when the difference in time lengthens.
NB: The transient nature of the original signal will influence the 15msec to 80msec range for replicated transient reflections. A transient snare drum may begin to sound discrete in the 50msec-80msec range, where a smoother sounding instrument, such as a cello or flute, will not generate reflections that will begin to sound discrete from the original sound source until at least approx. 100msec. The amount of high frequency content at the front of the original sounds waveform and the tempo of the music are also influencing factors in determining a sense of dimension in an enclosed environment.
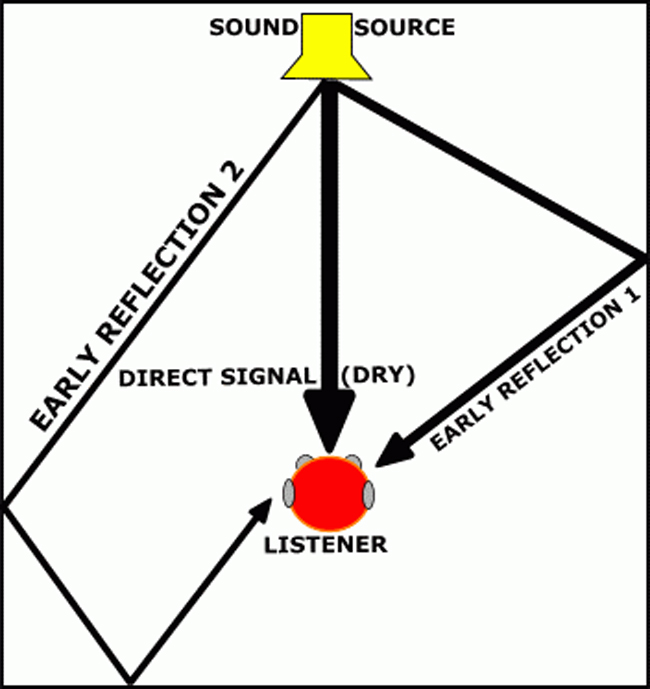
Figure 3: Direct Sound and Early Reflections
Reverberation
When sound is generated in an enclosed environment, multiple reflections become so abundant they will eventually merge into a highly diffused sound know as reverberation. This is most noticeable when the original sound source discontinues performing and the original sound continues to reflect from all surfaces, finally developing into reverb, which eventually decreases in amplitude until sound can no longer be heard. The time it takes for the sound pressure level of the reverberation to drop or decay by 60 decibels from the level of the original sound is known as the reverberation time, or RT-60.
As shown in Figure 4, in an illustrative listening environment, sound waves emitted by a source reach the listener both directly, via the on axis path between the source and the listener, and indirectly as reflections from walls, floor, ceiling, or any other reflective obstructions. This collection of reflected sound waves, which may total several hundred, eventually develop into reverb.
The collection of reflected sound reaching the listener varies as a function of the shape of the room, as well as the materials from which the room surfaces are constructed of (absorption coefficients) and the frequency content of the original source. Reverberation can also be used as a cue to source distance estimation and can present evidence on the physical make- up of a room (i.e., size; types of surface materials used on the walls, floor, and ceiling).
The number of times a wave is reflected before it reaches the listener is known as its order. The direct sound has an order of one; of sound arriving to the listening position. In a typical situation, the number of reflections will eventually generate into several hundred. A reflected wave is represented by its order of multiple reflections. In many situations, a higher reflection order indicates a reduction in the intensity level due to absorption by the reflecting surfaces and the inverse square law characteristics of the propagating waves.

Figure 4: Direct Sound, Early Reflections, and Reverberation
Reflections arriving later than 80msec, with orders greater than one, are known as late reflections or more commonly as discrete reflections. As the direct path sound decays, the initial sound of the reflections and reverb will sometimes be louder than the decay of the direct sound, thus appearing enmeshed or at times detached from the decay of the direct sound. Late reflections, arising from reflected reflections from one surface to another, are assumed to arrive equally and diffused from all directions with even amplitude to both ears and can be described as exponentially decaying sound or otherwise reverb. (RT-60) (Figure 5).
The reverberation term RT-60 can be defined as the time required for the sound pressure level (SPL) to decay by 60db after the initial burst of sound. The sound characteristics of the reverb depend on the shape of the enclosure, the material of the walls, floor and ceiling, and the number and type of objects in the enclosure. Depending on the level of the background noise, there may be a situation where reflections arriving after RT-60 are still audible. The decision to use the 60db figure was selected with the implication of a suitable first-rate sounding environment such as a concert hall. In such a situation, the loudest amplitude reached for most orchestral music is approx. 100db (SPL), while the level of background noise is approx. 40db. As a result, a reverberation time of 60db can be seen as the time required for the loudest sounds of an orchestra to be reduced to the level equaling the background noise.
Reverberation time is definitely influenced by the type of reflective surfaces encountered by the propagating waves. When a surface is highly reflective, very little energy is absorbed by the surfaces and the reflected sound will retain most of its energy, with this leading to long reverberation times.
In contrast, highly absorptive materials will absorb a great deal of the energy of a sound wave. When sound comes into contact with the absorptive materials, the energy is greatly reduced in the reflected portion of the sound, thereby reducing the overall reverberation time and amplitude. Late reflections will be become highly diffuses as the distance between the initial sound source and listener increases where the amplitude of the direct sound decreases until it is perceived as equal to the amplitude of the diffused reverb.
If an environment were filled with only with highly reflective surfaces and had no openings for the sound to escape, one could theoretically create an effect in which the sound would seem to last forever, for it is a fundamental law of energy we are concerned with. Therefore one must analyze what is occurring within the sound of reverb while it is decaying. If one analyzes the frequency response of the sound of reverb at the 1sec mark and then at the 3sec mark, one will conclude that over time, the high frequency content will decrease as the reverb amplitude decreases. The extent of loss of high frequency content and reverb time duration would be determined by the absorption coefficients of the reflective surfaces.
Reverberation contributes a gratifying quality to music with the idea of extending the duration of a melodic idea, which is very attractive to in numerous genres of music. Many digital software applications and even home theater system options employ tools that assist in enhancing the quality of music through the additional feature of offering more reverberation.
Today, engineers need a thorough understanding of all the elements that contribute to establishing a sense of distance and reverb dimension in order to create a surround sound mix that realistically emulates the sound experience one would perceive in an outstanding listening environment.
NB: The type of material used on each surface in an enclosed environment (absorption coefficients) dictates the frequency content and amplitude of the reflection/reverb. The softer and rougher the surfaces, the duller and shorter the reverb will be. If the surfaces are made of wood, the reverb will sound warm and not contain as many high frequencies. Concrete and glass produce a brighter reverb with a longer reverb time (RT-60). As the reverb time decays, the high frequency content in the reverb decreases. Across distance and time, the atmosphere absorbs high frequencies, and as the reflections bounce from surface to surface, the reverb diffusion increases. In other words, as the reverb decays so does its high frequency content and amplitude, no matter what type of surfaces are utilized to create a sense of dimension.
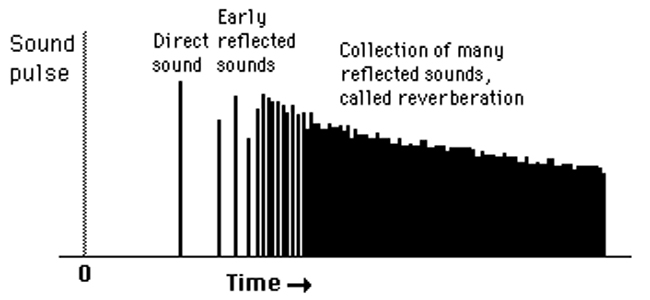
Figure 5: Amplitudes of Direct Sound, Early Reflections, and Reverberation
Auditory Distance Cues
The following auditory distance cues perform functions in the perception of the distance and dimension of an enclosed reflective environment, with both the listener and the sound source in stationary positions:
- Intensity of the energy emitted by the sound source (amplitude).
- Reverberation amplitude (direct path energy-to-reverberant energy
- Frequency content emitted by the sound source
- Binaural differences (e.g., ITD and ILD)
- The dynamics of the originating sound
Source intensity (amplitude) and reverberation are thought to be the most effective factors in determining distance between the originating sound source and the listeners position; however, any number of these auditory cues may be present where specific cues may dominate others depending on the type of listening environment. As a result, auditory distance perception may be influenced by such factors as the users familiarity with the rooms reflective surfaces, as well as the quality of the sound stimulus and the distance estimation calculated by the listener. In addition, changes in these cues may not necessarily be caused by an alteration of the distance between the listener and the source, but rather, may result from differences in the spectrum emitted by the source (e.g., the source audio is reduced) or modifications to the source spectrum due to differences in the environment, thereby further confusing matters, which can lead to poor judgments in source distance estimation. As source distance is increased, the intensity of the sound received by the listener decreases. However, intensity of the sound waves received by the listener may also decrease not exclusively with an increase in source distance, but also with a decline in source SPL intensity. In such an ambiguous situation, the user may not necessarily be able to discriminate between the two scenarios. Fortunately, as described below, the presence of other auditory cues may assist the listener in making a precise verdict.
It appears that auditory distance investigations should be conducted in standard reverberant environments. Source distance cues can be divided into two groups, exocentric, and egocentric. Exocentric or relative cues provide evidence with respect to the relative distance between two sounds, whereas egocentric ones provide information about the actual distance between the listener and the sound source. Consider a sound source and a listener in a room where the listener cannot see and does not have any prior evidence concerning source position or distance (Blind test). Now imagine the source distance is doubled. An Exocentric cue uses the decrease in sound intensity between the sound source at the initial location and the sound source at the new location to determine whether or not the distance has increased. On the other hand, with an Egocentric cue, the listener uses the ratio of direct-to-reverberant levels to determine the source is, say, three meters away from the listener. With a firm understanding of the relationship between the direct sound and its associated reflective properties an engineer will be able to determine and also create a listening position in relation to the direct sound source. Therefore the engineer may utilize both Exocentric and Egocentric principles in creating distance and a sense of dimension in the creative archetype of surround sound mixing.
The Waveform
Knowledge of the audio waveform elements e.g., amplitude-dynamics, time duration, and frequency content are imperative for optimizing ones ability to create dimension in surround sound mixing. There are four sections of the waveform to analyze and relate to how generate outstanding sound in a quality enclosed reflective environment.
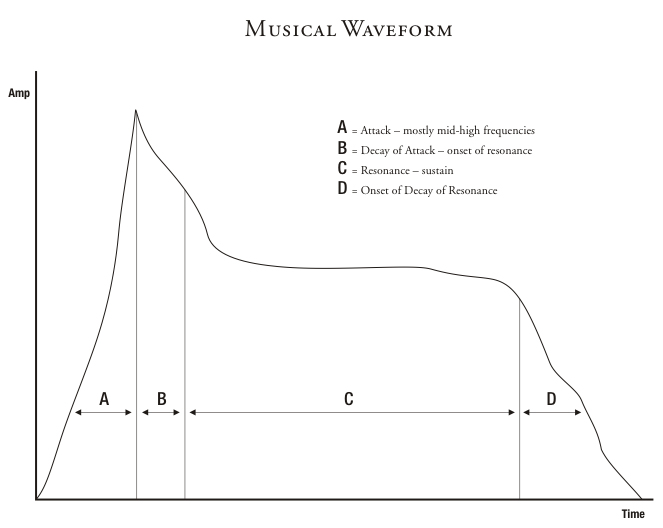
Figure 6: The Audio Waveform
The Attack A
In most audio waveforms, the attack (A-section) is composed of mid-high frequency content with little of the mid-low frequencies that are associated with fundamental music tonality. When analyzing the waveform of a note played on the piano, the first sound one would hear is the attack of the hammers hitting the strings producing overtones that are typically unrelated to each other. This attack would sound very percussive and almost noise like in nature when heard isolated. The frequency content of the A section would generally all be above 2khz.
Once the strings have been struck, they start to vibrate and produce resonance, better known as a musical note (B-section). The strings then excite the sympathetic soundboard, which produces a fuller and louder resonance for the struck musical note and its related overtone structure (C-section). The frequency content of the B amp; C sections would generally be all below 2khz. After the pianist stops playing, there will still be sound in a reflective sounding environment (reverb) (D). The frequency content of the D section would generally be all below 1.5khz.
With a drum, the attack occurs when the stick hits the drumhead. Like the piano, the attack portion of the sound is percussive with noise like characteristics, for two solid objects are coming into contact with each other create to create sound.
After the attack, the top and bottom drumheads will vibrate and generate resonance within the drum. If the drum is in a live sounding recording studio, the drum sound in the room will continue to resonate with early reflections and reverb.
In a lead vocal performance, words beginning with hard consonants like the word Time have no tonal content in the A section of its waveform. Almost all pitch generated by a vocalist is with the sound of vowels (ime). In the word Time the T consonant contains mostly noise characteristics, whereas the vowel I contains tonality, which is a sound defined as musical pitch. In editing dialogue the engineer can precisely take any word that begins with T and by its sonic character, use it in other words in the dialogue that begin with Ts. This is not true for vowels such as O or U for they contain tonality associated as pitch.
With music, the attack A section of the waveform defines the rhythmic element of a performance. If a pianist plays quarter notes at a fixed tempo, a situation could arise where the engineer could desire to alter the pianos waveform so its playing more of a rhythmic role than a harmonic/melodic role in a song. The engineer can achieve the desired effect by manipulating the attack section of the waveform of each note through signal processing such as equalization and compression. In the waveform of the piano, the attack section (A) has considerably more mid-high frequency content than the sustain section (C). Therefore if the engineer boosts frequencies above 2khz then only the attack section of the entire waveform will be enhanced. As the piano chord sustains and then decays, so does its mid-high frequency content and amplitude in relation to the attack section. When the piano is played forcefully with dynamics, the attack portion of the waveform increases in mid-high frequency content in relation to its amplitude. The harder the pianist hits the note, the further brighter the sound of the attack.
An additional technique to create an effective rhythmic role in a song is to use dynamic compression: compress the piano with a med-slow attack time and med-slow release time in order to elevate the amplitude of the attack (A-section) in relation to the amplitude of the sustain section(C). With the additional EQ boost in the mid-high frequency range, the listener will barely notice any tonal or amplitude change in the sustain and decay sections of the waveform (Camp;D). This signal processing procedure is to equalize the uncompressed part of the waveform of the piano in order to enhance the attack section of that is not compressed so that only the rhythmic elements of the piano performance waveform are enhanced.
If one wanted to emphasize the sustain element (C-section) of a piano chord, then dynamic processing of the signal would obviously be different and opposite to the above signal processing. In a production where there is a rhythmic picking guitar, the piano might supply the main harmonic content of the production. In this situation, the sustain part of the waveform (C-section) would have to be enhanced. The engineer will compress the piano with very fast attack and fast release times, as this will lower the amplitude of the attack section (A) in relation to the sustain section(C). And then equalize the sustain section(C) in the frequency range 200hz-2kHz for enhanced musical tonality.
The Decay of the Attack B (onset of resonance)
This part of the signal is a mix of the decay of the attack and the onset of resonance and pitch (B- section). With a piano as the attack part decays, the first sign of pitch begins to become audible. The change from the A to B sections occurs so quickly that it is not noticeable to normal human hearing.
The Resonance/Sustain C
This part of the signal is the sustain portion that contains the resonance and pitch of the sound (Music), and its where vibrato and tremolo occur. It is also here that compression is used to control overall volume management of the sustain portion of the sound in order to minimize random and extreme dynamics, allowing the sound-instrument to be heard more evenly in amplitude throughout the song.
The amount of high frequency content and overall amplitude in the sustain portion of the wavelength does not change as dramatically as the attack portion of the wavelength. The differences in attack amplitudes only subtly influences the frequency content and amplitude of the sustain sound section; where in most listening situations the difference is hardly noticeable.
With a snare drum this is the point in the drum waveform for sample enhancement. Try the following; take your favorite drum sample and remove the attack portion of the waveform (A-section) and trigger the sample with a key input from the original snare drum. This allows one to retain only the attack of the original drum and enhance the attack decay and duration of the sound with the additional sample.
The sample creates an image of louder amplitude through sound duration instead of the sounds peak amplitude, and in all cases, the amplitude of the sample is never as loud as the original snare drums attack. This allows the engineer to create a bigger snare drum sound without having to worry about peak distortion.
This also works with combinations of keyboard instruments. For one harmonic performance I have often linked through midi, a grand piano and a Fender Rhodes. I use the piano for attack (A) and the Rhodes for sustain (C). I then mix both instruments to a balance I desire, where at times I will feature the Rhodes in the verses and the grand piano in the choruses.
The Decay D
This part of the signal is the decay portion that occurs when the source instrument stops performing. Most of the audio content of this decay is the reflective sound-reverb generated in the enclosed environment. In a typical concert hall, the decay can be as long as 2.5sec, but it can be shorter than a 0.33sec in a small room environment.
To conclude, most instruments are capable of providing a combination of roles in music production; rhythmic, harmonic and/or melodic.
Designating which of the three roles an instrument will perform is critical in the stage of pre-production. With approved performances, the alteration of an audio waveform can be used to augment a harmonic, melodic and/or rhythmic idea, which can be further enhanced in the final mixing stage by the engineer.
Breakdown of an Audio Signal in an Enclosed Environment
An audio signal takes numerous different paths in an enclosed environment to reach a listeners ear.
- The direct path signal from the originating source to the listening position.
- The early reflections from walls, ceiling, and floor
- The many diffused reflections emanating from the direct sound and early reflections contribute to what is known as reverberation.
The unobstructed direct signal is always the loudest, and it is the most defined in its frequency response and easy to perceive variations in amplitude. The time it takes for the signal to travel from the source to the ear is determined by the speed of sound (approximately 1 meter/sec). If the direct audio is perceived as located dead center in a stereo or surround image, then the audios arrival time to both ears are identical. (ITD and ILD) If the direct sound is perceived to be coming from the left, the listener will confirm the location of the source; for the audio signal will arrive to the left ear slightly sooner and louder than the right ear (ITD and ILD). If a direct sound arrives from the rear right the listener will also be able to distinguish the correct location through the ITD and ILD process. It is also important to note that if an obstacle blocks the direct sound, the exact location of the sound source is difficult to determine and the listener will have to rely on the early reflections and the reverb to approximate the location.
As distance is added, the sound not only loses amplitude but also its high frequency content because of atmospheric conditions and loss of energy over time and distance. This allows the ear to recognize and conclude that the sound source is moving further away when heard out in the open and in an enclosure.
The first indication of dimension is when reflected sound arrives at a lower level and between 15msec and 100msec from the arrival time of the direct original sound. As previously stated, if the reflection arrives sooner than 15msec, it wont create dimension but will create imaging and exact localization problems. If it arrives later than 100msec, it will be perceived as detached and as a distinct sound experience.
The amplitude, time duration and frequency content of the early reflections and reverb determine the size of the enclosure and the type reflective materials of the enclosure.
In listening enclosures, the first early reflections, will typically arrive from the left and right walls. In most circumstances, the two delay times will be slightly different from each other, yet clearly distinct from the direct signal if they arrive at least 15msec later than the original direct sound. As previously stated, the reflections frequency content is always narrower (less high frequency) and lower in volume than the direct path signal, with the amplitude and high frequency reduction based on the absorption coefficient properties of the reflective surfaces of the enclosure and the distance traveled.
In a situation where the listener is situated at a fixed distance directly in front of a sound source, exactly between the left and right walls of a concert hall, the entire audio experience will contain an early left reflection and an early right reflection. Both reflections will create a sense of distance originating from the sound source and will also contribute to the development of reverb, which adds a sense of dimension. Both early reflections will lose high frequency content for the materials used in the walls of a concert hall are designed to absorb the higher frequencies of the early reflections in order to provide accurate imaging and develop a smooth and warm type of reverb in the hall. If the listener is sitting at distance from the stage but dead center, theoretically the left and right early reflections should arrive exactly at the same time. However due to the shape of the human head and the fact that the head is always slightly in motion, the arrival of the left and right early reflections are not exactly identical at any one given time. There is always a minor difference which results in random fluctuation of arrival times between the left and right reflections to the listening position.
In an example where the originating direct path sound arrives to the listeners ears at 5msec and two early reflections from the left and right walls arrive extremely close together within 25msec of the initial sound burst, there will be a difference of 20msec between the arrival of the direct path sound and the two early reflections.
With the addition of the 2 early reflections arriving at a later time than the direct sound, the listener will perceive that they are listening at a certain fixed distance, dead center from the sound source in a reflective enclosed environment.
If the listener moves a couple of meters from the center position to the left, the left reflection will be louder than the right reflection and the left reflection will arrive to the listener slightly sooner and louder than the right reflection. This will create a situation where the listener will perceive they are close to a reflective surface located to the left of the listening position. There will still be an early reflection arriving from the right wall but it will be slightly later and not as loud as the early reflection coming from the left, Therefore the early reflection coming from the right will only add a sense of dimension and distance to the overall listening experience. The direct sound will still sound like it is heard dead center when the listener is facing directly on axis to the originating direct sound. If the left and right early reflections were swapped with each other, the listening position would be reversed and the listener would conclude that he is situated close to a reflective surface located to his right.
The variables that will influence the distance between the listening position to the sound source and the type of materials the surfaces of the enclosed environment are constructed from are:
- The time differences; between the arrival of the direct sound and the two early reflections and the reverb
- The volume differences; between the arrival of the direct path sound and the two early reflections and the reverb
- The high frequency content differences; between the direct sound, the two early reflections and the reverb
- The reverb duration time of the enclosed environment (RT-60)
These variables can be controlled and manipulated by the engineer anywhere from the original mic placement setup and/or in the final mix where the engineer can alter:
- The timing between the different mic placements executed through moving of the original placement of the audio waveforms
- The different amplitudes of all the various mics
- The frequency content of all elements
- Additional use of artificial reverb.
It is important to understand how the ear determines distance from the sound source especially when the amplitude of the direct sound diminishes and the amplitude of the early reflections and reverb increases in relation to the decay of the original direct sound.
It is important to note that the amplitude and high frequency content of the early reflections and reverb, can never be greater than the amplitude and high frequency content of the direct signal as heard by the human ear in an enclosed environment.
When left and right delays are generated to substitute as early reflections are of identical value and both within 15msec-80msec of the arrival of a mono direct sound, listeners perceive the direct sound and both delays to be coming from one location and all audio will be heard as mono in a mix. When the direct sound source and the two early reflections are only heard in mono, it is very difficult to perceive a sense of distance and dimension that would be better established if the early reflections could be heard in stereo with the original sound source remaining in mono. If the instrument were stereo along with left and right delays (reflections) of identical value, there will be a perceivable yet limited sense of distance.
In a real life listening situation the right reflection and the left reflection would never be identical in time and amplitude for it would be impossible for the left and right reflections to arrive to both human ears at exactly at the same time, same amplitude and with identical frequency content. Thus, if one wants to create dimension in a stereo environment, liberties need to be taken when using digital delay settings to generate left and right early reflections, in order to create a sense of distance and dimension.
One method is to take a stereo-recorded instrument and add two delays (early reflections) of different values that follow the suggested guidelines. If the instrument were a stereo- recorded piano and left and right delays set to 30msec each, the delays would directly follow the original stereo panning of the piano. This method would create an unsatisfactory quasi-sense of distance and dimension.
One method of creating a sense of distance and dimension with a localized mono direct sound source is to place the original signal in the center position and create two delays at least 15msec and less than 100msec later than the arrival of the original sound source. Remember that a delay of less than 15msec from the related sound source will produce phasing and poor imaging effects and a delay of more than 100msec will create the illusion of a separate discrete delay and will not contribute in creating a sense of distance and dimension.
Pan the original signal to the center with the delays panned hard left and hard right at a lower level with some high frequency content rolled off. An Important factor when left and right delays are needed to emulate early reflections is that the delays cannot be of the same value and at least 15msec separately from each other to prevent phasing and image problems. If both of the delays are of the same time value and panned hard left and hard right they will collapse into mono and this will not effectively create dimension. Therefore in creating dimension; set the left delay at 30msec and the right delay at 45msec (or vice versa). Theoretically, the right delay (45msec) should be slightly lower in both volume and high frequency content, but for the purposes of creating dimension, it is unnecessary to apply this theoretical principle, because listeners most likely will not be hearing just one instrument in a mix or be in a listening situation to detect the exact location and frequency content of the delays (early reflections). The dimensional effect created by the 30msec (left) and 45msec (right) delays will greatly over-ride the time difference of the 15msec between the two delays.
If the left delay is 30msec and the right delay is 35msec there will be imaging and possible phasing problems between the left and right delays. If the both delays are quite different in set times (15msec-left and 80msec-right), it will create an unrealistic and undesirable listening environment, as if the listener is situated right next to one highly reflective surface.
To make the listening position appear even further back from two reflective walls, use a left delay of 75msec and a right delay of 60msec, with both delays at a lower level and with slightly less high frequency content than if the delays were set at shorter times. It is important to set the amplitude of the delays at a level where they will be only be perceived as supporting a sense of distance and dimension. If the delays are almost as loud as bright as the direct sound it will make the overall sound confusing and create the illusion that there might be rhythm discrepancies within a performance (flams). As previously mentioned, even though there is a difference of 15msec in the arrival times of the left and right delays, the dimensional effect will greatly override the 15msec time delay difference in relation to the fixed listening position, particularly if the direct sound is panned in the middle. If the sound source is stereo a sense of dimension will also be created. With two delays, and the associated altered frequency response and amplitude settings, a sense of depth and distance is added to the original direct sound to create the dimensional effect. I should also note that the type of volume and frequency of the beginning of the sound envelope of the original sound source, be it a percussive attack or a slow attack must be factored in establishing the time setting of the two delays for it will determine whether the early reflections (delay times) will sound dimensional or unfortunately discrete and messy. Furthermore, the frequency content of the delays will determine the absorption coefficients of the reflective surfaces.
These delays (early reflections) alert the psycho-aural response in a way that tells the listener that they perceive the sound at a set distance in an enclosed reflective environment. When the listener hears only the original sound, without reflections or reverb, the psycho-aural response would suggest that the audio being heard would have to occurring meters apart between the sound source and the listener elevated in the middle of a field at an elevated height. The only sound changes possible would be high frequency content and amplitude depending how far apart the source sound and the listener are from each other.
Reflected audio that sounds dull and dark suggests the listener is in an enclosed environment that has reflective surfaces which absorbs the high frequency content such as wooden walls. Reflected audio will sound brighter if the reflective surfaces are made of something firmer, like glass or concrete. Sound that bounces off surfaces always sounds less brighter than the original sound no matter what type of material the reflective surface is composed of, for every type of surface absorbs at least some high frequency content and amplitude. The duller the sound is of the reflection, the higher the absorption co-efficient of the reflective surface materials.
Discrete delays are easy to localize in the stereo image but will prove to be distracting unless the delays are used to enhance a rhythmic idea from a performance at a fixed tempo. So, if one pans a delay arriving at 200msec or later to the left side, it will be heard distinctly as if its directly and discretely arriving from the left.
This will not help create dimension, for the reflection will sound detached from the original sound source event. In order to add dimension to the sound of a percussive instrument, such as a snare drum, the delays (reflections) need to be in the vicinity of 15msec–50msec because of the transient nature of the sound of the drum (waveform). If the delays are longer than approx. 60msec, they may possibly sound totally discrete, because one would now hear the discrepancy between the transients of the original snare drum and the onset of the transient of the generated delay, which would result in a random and confusing sound. A good rule to remember for adding dimension to percussive elements is this: the faster the attack of the sound envelope, the shorter the delays (reflections) need to be to prevent the discrete delay from creating an overall puzzling and muddled sound. If one wanted to simulate a canyon like echo effect, then feel free to add discrete delays longer than 100msec, but make sure they are duller and at a lower volume than the original sound, as well as at a time setting that is not a rhythmic factor in the tempo of the music (in a rhythmic delay situation, the delay will likely land on a half, quarter, eighth, or sixteenth note of the tempo and will be masked by the rhythm of other instruments, which will make it hard to hear as a rhythmic delay effect linked to the original sound.
The faster the transient of the instrument, the shorter the delay needs to be used to generate early reflections to create dimension in a mix. If the instrument happens to be a piano, guitar or violin, delays can be between, left 15msec-80msec and right 15msec- 80msec, with a 15msec time difference between the left and right delays. For instruments with fast acting transients the delays should be between, left 15msec-50msec and right 15msec-50msec with a 15msec time difference between the left and right delays.
Another application to follow is: when adding longer delay times, dampen the high frequency content of the delay as the delay time increases. If the delays for one environment are 20msec and 35msec and you want to modify them to 50msec and 65msec than remove more high frequency content by lowering the high frequency roll off and mix the delays in at an even lower level. With plenty of instrumentation, the listener will barely notice the minor change of delay times and small change in EQ but will notice a variation in dimension. This technique also creates the illusion that the delays (reflections) have lost more high frequency content because the reflected sound has traveled further than a setting with shorter delays. Removing high frequency content from the delays will also simulate the type of surfaces the reflective walls are composed of.
Most concert halls and performance centers have a variety of reflective surfaces within their environments. In Toronto there are two performance centers used for classical, jazz, soft rock and pop music. Massey Hall is an older structure where the walls are mainly composed of wood and soft plaster. The acoustics of Massey Hall have been described as warm and rich sounding. The other performance center is Roy Thompson Hall, a newer building where the walls are composed of concrete and glass where the acoustics have been described as bright and at times confusing.
Therefore the delays frequency response used to generate early reflections will dictate the type of material of the reflective surface used in the listening environment. The delays times will dictate the size of the hall and how far the reflective surfaces are from the original sound source and the listening position.
Mix engineers have the ability to alter the frequency content and amplitude of the delays in a way that suits them to simulate a type of desired listening environment with a sense of distance and dimension, and the creative use delays works very well with all genres of music.
Stereo Dimension Conclusion
Before we move in to surround sound, a conclusion can be made for creating dimension for stereo mixing by emulating reflections through the use of digital delays. When the mix engineer assigns separate delays (early reflections) to vocal(s) or instruments recorded either in mono or stereo, he can then create a sense of distance and dimension for the original musical performance. The two delays to be generated need to be between 15msec and 100msec and at least 15msec separate form each other. The delay time stings, amplitude and assigned high frequency roll-off of the delays will imply the type of material the reflective surfaces are constructed of and how far the distance of the surfaces are between the listener and the source sound.
Surround Sound
The best sounding mixes in surround have the type of perspective where listeners can visualize distance and dimension in a surround sound listening environment. To achieve this, the mix engineer needs to understand how direct sound, reflected sound, and reverb work in combination with each another. In other words, how can the engineer relate and use this knowledge to achieve a desired dimensional perspective in a surround sound mix? Sound design, ambience, Foley and dialogue are mostly mono or stereo elements then altered and adapted to create a surround sound image. As previously stated, once an engineer comprehends how sound works in a three-dimensional environment he will also have the ability to take mono and stereo elements and generate a surround sound mix.
When sound is projected from a source location, a listener will first hear the direct sound, then early reflections and reverb. Once reflections regenerate where they become so dense that listeners can no longer distinguish them as discrete reflections, these numerous reflections evolve into highly diffused reverb. To create dimension effectively in this situation, one needs to analyze the music in a three-dimensional perspective rather than a two–dimensional one. A listening environment in surround sound will function considerably more advantageously in creating distance and dimension than in a stereo one. Through the resourceful use of signal processing in a mix (amplitude, frequency response, and time duration), the engineer may acquire the rudimentary and essential knowledge that allows for creating distance and dimension in surround sound mixing. However, fundamental laws of physics govern the process of creating a realistic sense of dimension. Therefore to create dimensional aural landscapes, an engineer also needs a fundamental understanding not only of how human hearing relates to sound but also how to manipulate the various functions required in creating dimension for a surround sound mix.
It some cases the techniques required to create dimension in surround sound are very unconventional and remarkably original. As they say, If you want to break the rules, you need to know the rules you are breaking. An outstanding example of being original is in the imaginative utilization of convolution reverb, which can be manipulated to achieve astonishing believable realism.
With a good understanding of the physics of enclosed environments, as well as the fundamental operational principles of audio processing, it is possible to create the illusion of virtually almost any listening environment that can be imagined. First, one needs to know how sound arrives with all its fundamental characteristics from a fixed location to a stationary listening position in an enclosed environment, and then recreate this model with all the dimensional characteristics for a surround sound mix. Figure 10 shows the layout of a concert hall with three different listening positions, A-B-C, all situated at fixed distances from the performance stage. The goal here is to determine which factors contribute to the overall sound experience with the listener seated at the three different stationary distances from the sound source. If a group of musicians are performing on a stage in a performance center, the listener will hear three different aural experiences when seated at the three different distances from the stage. The quality of the direct sound, early reflections, reverb, high frequency content and amplitude will all be considerably different between one fixed listening position and another position. Once an engineer understands why the three listening experiences are different, he will then be acquainted with the knowledge of the fundamental factors and how they differ and relate to each between one listening location and another. The engineer will then be able to manipulate specific audio processing to create dimension, so instead of the engineer (listener) having to change his location of listening positions to hear different dimensional perspectives, he can remain in one fixed position and create distance between the different instruments and vocalist to achieve a sense of dimension between the individual instruments for a surround sound mix. If the engineer can determine which rules of sound that are involved and how they contribute and determine the type of listening experience for each listening position, the engineer will then be able to reverse the situation and mix a performance where the musicians are placed at different distances in the mix from his fixed mixing position (listeners position). So instead of the listener having to move to different positions to hear different characteristics of the overall listening experience, the listener (engineer) can then take this knowledge and situate the listener in one position and have the musicians placed at various distances in the mix. For one example, the engineer can build a mix where the lead guitar sounds like the listener is sitting very close to the stage in the A position, the drums have the listener situated further back in the B position and the synthesizer in the C position therefore creating different distances and perspectives for various instruments in a surround sound mix.
I recently mixed music for the world famous Cellist Yo Yo Ma for a film that presented perspective problems that needed to be corrected from the original mix. The original session was recorded in a concert hall with various mics in various locations. The engineer who recorded the original session followed standard conventional recording techniques that are used throughout the classical music genre.
The recording engineer used a close microphone on the cello, a Decca tree, flank mics and ambient hall mics.
Once the engineer obtained all his recording levels he then assembled a mix of all the mics and stuck with one fader setting for the entire recording. The engineer concluded that the best sounding mix consisted mainly the ambient, flank and Decca tree mics, as the best desired balance for the listeners taste (no use of the solo cello spot mic). After auditioning parts of the recording, I convinced Yo Yo Ma that using one fixed fader (location) position that focus too much on the ambient mics for the entire recording was not effective in translating the emotional and intimate feeling of the performance and fell far short of achieving the finest quality of a sound experience for the listener. However I did approve of some of the recording engineers balances of mics for some sections of the recording. Still the problems with the one-fader position for the mix were these:
- When Yo Yo Ma was performing parts of the music score that featured him as a solo, the overall sound on the cello was too distant sounding and lacked presence and intimacy. The sound was also too reverberant and low in amplitude.
- When Yo Yo Ma was performing ensemble with the entire orchestra at a loud level, the sound was too distant and reverberant, harmonically messy, with the Cello much too low in amplitude in relation to the orchestra.
- The one-fader position only sounded acceptable when the orchestra without the cello was performing at a moderate level and medium tempo.
- The conclusion that was reached to achieve the optimum mix was when the cello was playing solo; the performance should be more present sounding with the cello marginally louder. When the cello was performing with the full orchestra at louder levels the overall sound could afford to be more reverberant with the cello slightly louder.
In the following descriptions, I will state the factors that contribute to determining the kind of sound experience that is occurring with direct sound, early reflections, reverb, levels and EQ at various distances from the performance stage.
Once this is comprehended, the engineer will then have the knowledge to create a sense of dimension for a surround sound mix.
Recording
Excellent orchestral recording requires a large enclosure such as a sound stage or large recording studio with excellent early reflections/reverb qualities that are necessary for high-quality surround sound recording and mixing. Sound stages and large studios possess advanced technology and are mostly found in the larger cities in the world. In North America, most of the music for film scores and TV are recorded in Los Angeles and in Europe, London, Berlin, Prague and Vienna.
Conventional standard approaches to surround sound recording use a method that captures the performance in a natural and exceptional acoustic environment. Orchestral recording is often the only music truly recorded and mixed for surround sound other than pop, rock and jazz live performances for a musical artists recording catalogue.
The standard surround sound recording integrates a combination of microphone pickup locations, so the engineer can control the balance between the different mic positions in the final mixing stage.
Engineers will often position 20 #8211; 30 spot or close microphones on specific instrument sections, just in case the composer wishes to feature a certain instrument in the mix. In addition, they additionally use the Decca Tree, two flank microphones, and at least two ambient room microphones.
The Decca Tree
The Decca Tree is where the recording engineer places three microphones (identical model) in a configuration directly in front of the orchestra above the conductor and which will be panned over the front channels, Left-Centre-Right.
This pick-up captures the orchestral balance as perceived by the conductor. The Decca Trees 3 mics can all be raised and lowered on one microphone boom stand.
Figure 7: The Decca Tree Microphone Configuration

Figure 8: The Decca Tree Microphone in the Studio
On most recordings, the pick-up pattern of the microphones is set to omni, where the height of the mics dictates the width of the stereo image and also the blend of direct path sound verses early reflections/reverb. The higher the Decca Tree the more reverberant the overall sound and also less stereo sounding. The Decca Tree is only one part of surround sound recording, for it mainly satisfies a stereo perspective form the conductors viewpoint, and any further surround enhancement would have to be done with additional microphones and/or created and synthesized by the engineer in a surround sound mix situation.
Flank Microphones
In addition to the Decca Tree there are two flank microphones on either side of the orchestra. The left and right flank microphones are identical large diaphragm condensers that are panned front hard left and front hard right, as this allows the engineer to increase the perspective of the stereo width in addition with the Decca Tree. If the orchestra seating stretches 21 meters across form one musician to another than the flank microphones should be approx. positioned 7 meters from the left end and 7 meters from the right end. So there would be a distance of 14 meters between the left flank and right flank mics. Obviously the exact positioning is dependent upon the engineers choice. This mic location placement also permits the engineer to position the Decca Tree lower to the orchestra for a tighter pick up, and let the flank microphones capture a wider stereo image. On most recordings, the pick-up pattern of the flank microphones is set to Omni pattern just like The Decca Tree.
However, if the Engineer feels he has too much room sound with the Flank mics in omni, he can switch the pick up pattern to cardiod and let the ambient mics capture the room sound. This pick up still only satisfies a stereo perspective and additional ambient mics are required for a true surround sound recording.

Figure 9: The Decca Tree with Flank Microphones
Ambient Room Microphones
An engineer will use at least 2 large diaphragm condenser mics to pick up the reverb characteristics of the recording environment. They are usually positioned equal distance from the back and sidewalls in order to pick up maximum diffusion of early reflections in the recording environment. The mics are placed at ½ way to 2/3 up from the floor. In some situations the engineer will use more mics placed in different positions to record the ambience of the hall. In some cases where the environment is too small and there is still a need for ambient mics, the engineer will at times aim the mics away from the orchestra towards the back wall in a cardiod position. This will allow the mic to not pick up any of the direct sound and only the reflections/reverb from the walls.
Spot-Close microphones
In almost all occasions it is essential that spot mics be used especially if certain instruments need to be featured in a performance.
Another contribution factor is the fact that certain instruments such as the oboe can only project so much volume due to its limited size, therefore when a full orchestra is playing mezzo forte (loud) the oboe will be hopelessly inaudible in the overall sound.
Spot microphones are condenser mics using a cradiod pick up pattern to maximize the pick up localization of the instrument. The mics are normally placed 1-2 meters from a solo instrument and 2-3 meters if the pick up is a group of instruments such as the woodwind section. In most recordings spot mics are used for the woodwind section, harp and vocalists (if used).
Microphone pickup in relation to audio waveform:
If one applied the microphone placement used in surround sound to the diagram of the waveform, one could conclude:
- The spot-close microphones would feature the A section of the waveform.
- The Decca Tree and the Flank microphones would feature a more equal combination of B amp; C sections.
- The ambient microphones would feature the D section of the waveform.
The engineers strategy in surround sound recording is to capture a performance through the use of microphone placement techniques that will enable him to achieve a sound that records all sections of the waveform for the final mix. Once this is achieved, it becomes a basic starting point for the entire music recording with the ability to enhance the different parts of the audio waveform with the different microphone pick-ups in the final surround sound mix.
Panning configuration of the microphones:
- Close-spot microphones positioned across the front channels, panned to where the section would appear in a
- Left to right image if one were facing the orchestra from the front.
- The Decca Tree is panned hard left-center-right across the front.
- The flank microphones are panned hard left and hard right across the front.
- The ambient (rear) left and right microphones are panned to the rear channels hard left and hard right.
Most engineers prefer an overall pick up that replicates an excellent listening experience in a first-class acoustic environment. Occasionally the engineer will increase in volume a section or certain instruments (spot microphones) in the final mix, if the composer needs a certain instrument or section to be heard clearly. With orchestral music this situation arises quite often when the solo instrument can only project with limited amplitude.
A harp, due to its physical construction can only project so much volume when its performing with a full orchestra, for it is very difficult to hear the harp performing with dynamics.
The final surround sound mix will sound like the listener is hearing the music positioned at a fixed distance from the orchestra in an enclosed environment. The engineer can mix the music where the listening position could be either ten rows back on the main floor, the first row of the balcony or in the very back row in a concert hall. If the music is more contemporary like a pop song, the engineer will strive for a sound that will have a sense of dimension to it, where the singer or soloist will sound like it is being positioned in front of the musicians.
In most situations the instruments/soloists are panned across the front and the rear channels will contain reverb from the ambient mics. This works well in theory, but at times it does not translate very well to the optimum listening position in a movie theatre (sitting approx ½ to the back from the screen). One problem with this approach is that a great deal of audio can be heard simultaneously in a film, from effects, dialogue, sound design and music that listeners barely notice the presence and articulation of any music in the rear channels. With most orchestral music, the engineer will pan the spot mics, Decca Tree and flank mics, across the front channels, with the ambient microphones in the rear channels. Also if artificial reverb is added it will be mainly heard in the rear channels. What might occur when this mix strategy is executed? Remembering that most of the viewing audience will sit mostly towards the back half of the theatre to appreciate a better view. They are situated there because they can view the entire screen without constantly moving there head and eyes back and froth between left and right. It is an obvious pun when the movie viewer says that sitting very close to the screen is literally, a pain in the neck. When sitting towards the back of the theater, music with fast tempos will sound harmonically undefined and confusing, because the ambience from a previous note/chord starts to mask the beginning of the next note/chord, and especially if the outgoing note/chord is louder than the incoming note/chord. In relation to the above diagram, the #8216;C part of the waveform elongates, gets louder, and overpowers the #8216;A part of the waveform in the next incoming signal.
Considering that the rhythmic characteristics of music come from the #8216;A part of the waveform, one can certainly hear how the rhythm becomes obscured, for the buildup of the resonance in #8216;C now masks the overall rhythmic clarity of the composition. When the envelope of the incoming note/chord has a slow attack time, the problem becomes even more exaggerated. A great deal of orchestral music mixed for film has only reverb in the rear channels which further exacerbates the situation, where the listener relates to listening to the music as if they were sitting at the very back of a live venue, where the reverb starts to wash out most of the definition in the music.
In some theatres, Ive noticed harmonic dissonance and an overall cluttered sound occurring because much of the ambience of the recording room microphones were used in the final mix. When the theatres own innate RT-60 is added, it extends the reverb time in the mid-low frequency range, which establishes an effect somewhat like a pianist playing at a fast tempo below middle C with the sustain peddle down all the time.
It was obvious to me that the engineers mixing position in the final mix was closer to the front monitors than the rear monitors where he increased the amplitude of the music assigned to the rear channels to compensate for a sitting too close to the front monitors.
In a good recording hall, a reverb time of approximately 1sec #8211; 2sec will be captured by the rear ambient microphones and often extended in the final mix up to 2.5sec-3.0sec with additional use of artificial reverb. If this mix is then played in a large reflective theatre, it may result in extending the RT-60 time closer to over 4.0sec sec and even longer for lower frequencies, generating a very jumbled and muddy sound. This might sound fine for slow tempos, but once the tempo increases, the music will sound harmonically confusing when it arrives to the viewer ears (listener). In addition, if the dialogue needs to be heard clearly in the final mix, all music channels will be mixed at a lower level whereby the first thing to suffer musically is the A-section (rhythm) articulation of the music waveform originating from the front speakers. And if the viewer is sitting towards the rear of the theater they will hear more of the reverb in the rear channels than the front channels and further complicating a clarity and intelligibility problem. Another contributing factor is the dynamics of the music when heard under sound design and dialogue. If the music is too dynamic the softer passages will sound undefined and at times not even audible. A good mix engineer will correct this dilemma by riding the level or using transparent compression to make sure the music is always audible and well defined.
As stated earlier, the A-section contains most of the musics rhythm (mid-high frequencies). Because the close spot microphones are situated closer to the instruments than the Decca Tree and ambient microphones, the signal coming from the close microphones will be the earliest sounding of the three pick-up locations. When I mix orchestral music for films, I create fader groups where I have the close microphones mix on one group master fader, the Decca Tree, flank microphones, and the ambient microphones on other group master faders. This allows me to achieve a balance between the articulation (A-section), sustain (C-section) and the reverb components (D-section) of the music in the final mixing stage. If the tempo is slow, I can add more of the flank and ambient microphones and elongate the duration of the music to fill out the composition with more sound duration (C amp;D-section). Often I will also add artificial reverb to the mix to create a more reflective listening environment by extending the overall reverb time (RT-60). If the tempo is fast, I will balance the close microphones, the Decca tree and flank mics and feature them in a final mix balance at a level where the rhythmic articulation is clearly heard on the sections of music that require it. I can also increase the level and decay time of artificial surround reverb if I need it to fill out the sound in the rear channels. As previously stated all the engineer needs in the final mix is a small amount of level from the spot microphones to emphasize the rhythm of the waveform (A- section). If the musics focus is more on its rhythmic structure than its harmonic structure, and is under dialogue, mixing in the close microphones will produce greater clarity in the music. Does the overall sound change? Yes, but not enough to notice to the average viewer. I am mainly adding the mid-high frequencies of the A-section of the close microphones to the mix, therefore the harmonic structure of the overall mix remain nearly the same. What one might notice when listening in a theater is the aural suggestion that the listening position to the actual orchestra is slightly changing in distance, which is a small price to pay for needed articulation and enhancement of the overall sound. If the tempo slows down, all the engineer has to do is reverse the process by adding more of the ambient microphones, artificial reverb and extending the reverb time.
In rock and pop music, engineers like to create a natural environment but they also like to source sounds creatively thorough localization of sounds. The placement of instruments and their own sense of dimension in various locations can be intriguing for the listener.
One could only imagine how Pink Floyds Album Dark Side of the Moon would sound in surround sound. Many progressive rock bands from the 70s featured panning instruments with their reverb across the stereo image, integral to their compositions and production techniques. However, the location of instruments and panning in different positions can also prove to be distracting if the main focus is a lead vocal. For example, it might sound cool if one listens to a lead vocal while the guitar is panning between the left and right rear speakers, but this panning could prove to be too distracting for others when the focus is on the lead vocal. When the lead vocal comes from the center, while the solo always comes from the front left can be satisfying as long as the guitar remains stationary. Jimi Hendrix loved to pan his guitar solos, but primarily only panned the solo when the lead vocal was not performing at that moment in the song. Remember, the ears work in a similar fashion to the eyes; you can focus on an object straight in front of you, but as soon as something enters the peripheral vision, the eye will change focus to whatever is moving. By all means place sound sources where you like, but make sure your production maintains appropriate focus and doesnt get distracted through panning and large volume changes.
Mixing Pre-Recorded Surround Sound
For movies with reasonable to generous budgets, there will likely be orchestral recording for the music score. Film composers will chose excellent studios capable of recording in surround sound for 5.1 mixing. In early 2013 the film The Lone Ranger was recorded in Abbey Roads famous studio #1 with over 70 musicians. It is a very large room with an excellent RT-60 with Isolation booths if needed. The recording consisted of spot mics, a Decca tree, sectional mics and many room mics to capture the ambience. Instead of using an isolation booth for the solo trumpet, the composer and engineer opted to overdub the trumpet with all the other mics used to record the entire orchestra included in the trumpet overdubbing. The intention here was to have the trumpet sound exactly like he was performing live with the orchestra. Recording the trumpet solo mic with all the other mics used to record the orchestra would include the desired leakage and ambience that contributed to creating the sense of dimension that would have been achieved if the trumpet was recorded at the same time as the orchestra bed track. When the film was mixed later in Las Angeles, the engineer simply had to pan the spot mics across a stereo image over the front speakers with the Decca Tree and room mics panned to their designated positions to replicate the placement of the mics in the original recording session. Artificial surround reverb was added sparingly and mainly used to extend the natural RT-60 of the studio.
With almost all surround sound mixing, the instruments are panned across the front left and right channels and the room mics panned to the rear left and right channels. Very little music is allocated to the center speaker and the LFE (Sub-Bass). Almost all music that appears in the front speakers is panned using a phantom center. What might potentially exist in the center speaker are minimal levels of the instruments and ambience/reverb.
When a film is in the final stage of post-production the mix will contain audio elements that make up a final 5.1 sound track.
The music will be premixed in 5.1 stems with potential breakdowns into separate stems of percussion, harmonic content and solo instruments (if used). All the post engineer has to do is set all the faders to 0-VU, to replicate the final mix of the music engineer. Stems are needed, if certain drum hits clash with the dialogue or sound design, then all the post engineer has to do is lower the level of the percussion stem a couple of db. This will allow the stem of the harmonic content of the music to remain at the same level. This prevents the undesirable task of having to lower the level of the entire music track, which might unfortunately be noticeable to the viewer. Obviously the composer and music engineer hope that there will be no changes to the final preferred balance of music.
The reason why music is not panned to the LFE is that the senior post-mixing engineer prefers to allocate the low frequency sound design elements to the LFE speaker system. Sound effects like to maximize the 20hz-40hz frequency range, with plenty of time duration which requires huge amounts of amplification power and very large speaker drivers for human hearing is not efficient in the lower frequency ranges. Effects like earthquakes, rocket launches and impacts need to be felt as much as being heard. With home theater systems bass management is employed that effectively redirects low frequency content below 120hz to a more powerful sub woofer to achieve a realistic effect.
There is musical frequency content from certain instruments in the 20hz-120hz range, but those instruments have harmonic overtone content that can be heard in a higher frequency range to establish what note the musicians are playing. For example a low A (27hz) on a grand piano contains generous content at 54hz and 108hz, where on mid size grand pianos, most of the content of a low A is contained in the overtones. Therefore it makes sense to conclude that the 20hz-120hz range works best with mainly sound design elements.
Another factor is since the post engineer has only music stems to work with, the center channel in the final mix might contain some music with the dialogue, with almost all dialogue localized in the center speaker. If the consumer at home places whishes to hear the dialogue louder they will be able to set the volume of the center channel louder. When this is done, any music in the center channel will correspondingly get louder. Because the center channel will mostly contain reverb, the overall music mix has the potential to sound too reverberant in the front, where the task of reverb to create depth should be dedicated to the rear channels. Therefore when panning music and reverb to the center channel, low levels work best. There should always be some low-level music and reverb in the center channel so the viewer sitting in the center and close to the screen does not perceive an audible dead spot in the music.
Live Music videos that have been mixed for surround sound follow the same panning template that is used for orchestral sound tracks. The front channels will contain all the instruments and vocals with the rear channels dedicated for creating dimension of the music through the ambient mics. What might be different is if there are lead vocals or solo instruments, where the mix should still enclose the vocal in a phantom center but also mixed to the center channel.
This helps focus the location of the vocal to a center position when the mix is listened to in various seating positions in a home theater setting. This also gives the home viewer the option of altering the volume of the center channel.
The mixing engineer also has the option to use signal processing such as EQ, dynamic management and FX that he would be inclined to use in standard music mix for an artists album release.
Film soundtracks that have been recorded in surround are somewhat easy to mix for the engineer is usually focused on levels, dedicated panning and possibly artificial reverb.
Creative Surround Sound Mixing
The evolution from mono mixing to stereo mixing is to a certain extent symbolic and indicative to shifting from stereo mixing to surround-sound mixing. The transition is challenging yet straightforward.
There are challenging mixing situations where a music recording does not include ambient microphones that could be used in a mix to replicate a surround sound environment. Films often contain pop-rock music hits that are only mixed in stereo, where post mixing engineers simply add surround sound reverb from the original stereo mix to the rear channels to generate a pseudo surround sound environment. Although this process creates an idea of an enclosed environment, it has many shortcomings, for it tends to render the overall sound too reverberant especially if the viewer is sitting towards the back of the theater.
There are growing opportunities for older recording catalogues to be mixed for car stereos in surround sound. There is also a need to simultaneously do a surround sound mix while completing a stereo mix for an artists potential use in a film/TV soundtrack. Overall, there are numerous justifications for mixing in surround sound using various audio elements and sources. Presently there are specific surround sound mixing strategies that allow the engineer to mix a song in surround sound, but are limited in creating a realistic enclosed environment. What is missing is an additional methodology of creating realistic sounding reflections and convincing reverb.
The goal and challenge now is to build a surround sound mix for music that contains stereo and mono elements (piano, guitar, vocals, drums…). What needs to be factored into the mix is the ability to generate early reflections and highly diffused reverb from the early reflections to contribute in generating an aural illusion of surround sound. The goal of creating an excellent surround sounding mix is the ability to establish a sense of distance and dimension. A lot of the planning is required in the initial setup of a surround sound-mixing template along with qualified use of appropriate signal processing.
The Surround Sound Template and Methodology
The surround sound template and related methodology focuses on creating distance and dimension for a realistic and entertaining surround sound experience.
With orchestral recording and live shows, the engineer can utilize ideal placement of microphones to capture the ambience required to replicate the sense of surround sound in a final mix. In the mixing stage, the engineer might also sweeten the mix with additional artificial reverb. This is a simple approach that only requires the engineer to follow basic essential rules of recording and mixing.
The more enhanced and representative approach to surround sound mixing requires the engineer to create an enveloping environment from mono and stereo sources. Its obvious that a simple surround sound reverb (digital) will create an environment with a fixed decay time (RT-60) that might offer the option of early reflections. But this undemanding approach is very limiting. If the engineer uses a surround sound reverb with one setting and exploits the use of it with all instruments, the music will sound like it is all heard in one fixed location in an enclosed environment. The final mix will nevertheless sound two dimensional, much like a finished stereo mix with added surround sound reverb.
So when speaking of creating distance and dimension in surround sound, the mixing engineer will need to utilize digital delays to create the sense of early reflections and equalization to reduce the high frequency content of the delays to emulate the type of material of the reflective surfaces. Additionally the type and operation of the surround sound reverb setting will assist in emulating a believable environment.
Generally, any delays (early reflections) will not affect clarity if they are equalized and mixed at appropriate levels. The addition of surround sound reverb to these delays emulates and enhances a realistic surround sound environment. This additional reverb, together with the correct pre-delay settings and equalization, allows engineers to enhance the accuracy of a surround sound environment.
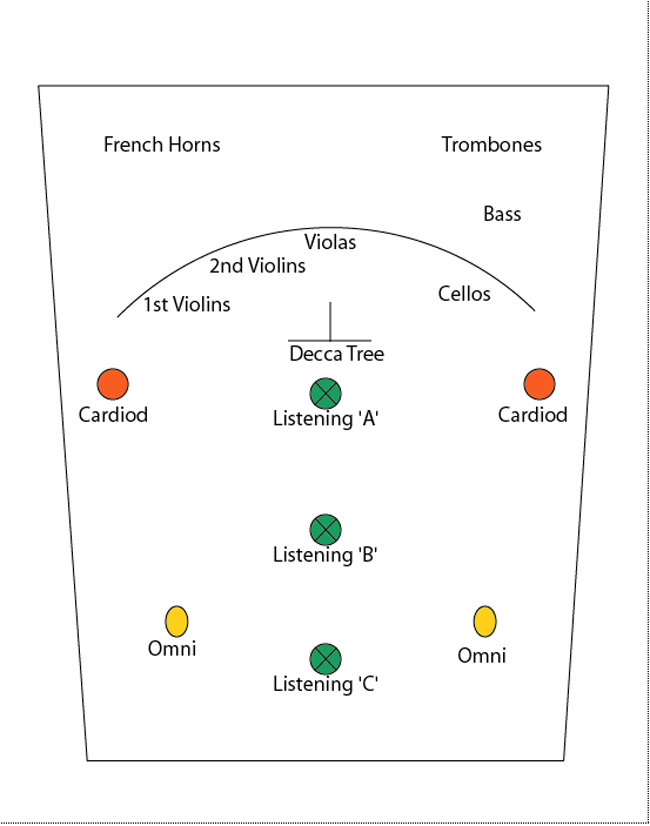
Figure 10: Three Listening Positions in an Enclosed Environment.
Listening Positions in an Enclosed Environment
In most performance halls the B position is regarded as the optimum listening experience. The listening position is chosen because it represents an accurate balance of direct sound, early reflections and reverb. In a concert hall this position is usually in the center of the first row of the balcony.
When Engineers record orchestral music for films, performance and CDs, this is the listening position they strive for in the recording and mixing process. This listening position is often referred to as the listeners sweet spot. As previously stated the B position is not truly the most optimum location when a music score calls for a solo instrument passage or when the tempo is very slow. When an oboe is performing a solo motif with the orchestra, it is often very difficult to hear the oboe clearly amongst all the other instruments. When the orchestra is playing Largo (slow tempo), objectionable and undesirable dead spots in the ambience may become dreadfully noticeable.
The goal is to explain how to create the B surround sound listening position from stereo and mono instruments. Using the B position as a reference point, the engineer can use slight alterations in equalization, delays and related amplitudes to relocate the listener to either the A or C listening positions. Since the listening experience is in a fixed enclosed environment, then theoretically the reverb time (RT-60) should remain identical for all listening 3 positions. The key changes that define the three different listening positions are primarily concerned with early reflections (delays), Eq and amplitudes. To enhance the sense of dimension in some of the positions, the reverb decay time should change but very slightly. The principal change in reverb will be with its high frequency content that emulates the properties of the reflective surfaces and its amplitude setting in how it relates to the delays and direct path sound. The pre-delay for the reverb also will significantly influence the listening positions distance from the sound source.
The B Listening Position
NB: The numerical figures assigned to set time values and equalization frequency points in all three locations are not exact and valued as approximate.
This B position is slightly in front of the exact center of the enclosure, 7-10 meters away from the origin of the fixed positioned sound source. In a typical concert hall, this position is usually the middle of the front row in the first balcony.
In most halls, the B listening position is regarded as the optimum listening position, which is why these seats are frequently the most expensive. This position is preferred since it represents an effective balance of direct sound, early reflections and reverb for the listener. When Engineers record orchestral music for films, performance and CDs, this is the listening position they strive to emulate in the recording and mixing process.
However the B position is not the ideal location when a music score calls for an instrument solo during the performance (concerto) or when the tempo is very slow. When a cello is performing a solo motif with an orchestra it can at times be incredibly demanding to hear the cello clearly amongst the excessive amplitude arising from all the other instruments. If the orchestra is playing at a Largo tempo (slow), silent gaps in the ambience may become prevalent and objectionable for the listener.
The earliest and loudest sound component heard in any listening positions is via the direct path route. Of the overall 100% of the total audio heard in the B position, approx. 70% of the total sound heard will come via the direct sound route. Due to the distance, the high frequency content will be slightly lower in response due to atmospheric conditions, so there will be a slight decrease in frequency content above 12khz.
The early reflections will comprise 15% of the total sound heard. There will be early reflections coming from both the sidewalls and rear walls, so delays have to be created to generate the impression of these early reflections. Remembering that all early reflections that arrive to the listening position need to reside between 15msec and 80msec to be effective, the engineer needs to create these discrete reflections through the use of digital delays. Another factor is that the dedicated set times of the delays (reflections) are based on the differences of arrival times of sound between the direct path route and early reflections (delays). In the B position all the reflections should be close together in value and frequency content since the rear walls are only slightly farther away than the sidewalls. In a respectable performance venue, the excessive elevated height of the ceiling does not contribute in generating early reflections. The floor is usually covered with highly absorptive materials, which significantly mutes the sound, so no reflections from the floor. In the delay setup, it is recommended that the audio return of the longest delay (#4) be reassigned pre-fade to send #1 (earliest delay). Although this will regenerate delays outside of the creating dimension range, the additional delays (reflections) will be much lower in level than the individual four delays. These additional delays will however enhance the realism of the reverb.
The Reverb component will make up the remaining 15% of the total sound heard. The decay time of the reverb is also an aesthetic choice, but it should be long enough in duration to be perceived as realistic ambience in a reflective environment and short enough to keep the mix from sounding harmonically confusing and unclear. There needs to be a high frequency roll off on the reverb return, for reverb is the summation of all the numerous reflections that lose more high frequency content with every regenerated reflection. The roll off frequency selected as the onset of diminishing high frequency content should be approx. between 3khz-5khz. The lower the roll off frequency point, the duller the wall surfaces reflections will be perceived. Most reverb processors reduce high frequency content, as the reverb decays over time. Therefore the high frequency content of the reverb will be a lesser amount at 2sec than it will be at 1sec.
Creating Dimension in the B Position
In session template setup, assign 4 mono sends to 4 mono return channels and insert a digital delay and equalizer over each channel. Assign all channel returns (delays) to the 4 corner speaker channels. (LF, RF, LR amp; RR)
Amplitudes
Direct Path Sound = 70% Early Reflections = 15% Reverb (RT-60) = 15%
Early Reflection-Delay Times
- Front Left Delay = 30msec-Send #1
- Front Right Delay = 45msec-Send #2
- Rear Left Delay = 50msec-Send #3
- Rear Right Delay = 65msec-Send #4
Equalization- Roll Off Point of High Frequency Content
- Front Delays Return channels = 6db/octave roll off @ 5khz
- Rear Delays Return channels = 6db/octave roll off @ 3khz
- Assign all 4 delay returns equally as post fade sends to the Surround Sound Reverb
Delay Regeneration
Return Channel #4 (65msec) = assign pre-fade to sends #1 thru #4
Surround Sound Reverb
- Decay Time = 2.0sec-2.5sec
- High Frequency Roll Off = 6khz
- Roll off all frequencies below 100hz (6db/octave) Pre-Delay = 35msec -50msec
For moderate tempos assign a reverb time between 1.5sec-2.0sec. Reverb time length should be set in regards to the musical density of the song and its tempo. The length of the decay time also depends on the mixers aesthetics.
Send all delay return channels equally to surround sound reverb Pre-delay needs to be 0msec for all reverb sends from all 4 channel returns All reverb sends from all 4 delay returns should be of equal level If reverb is sent directly from instrument channels to a surround reverb processor with similar settings that are being used for the surround reverb for the 4 delay returns, then the pre-delay send must be longer than 30msec. (It is impossible to hear reverb before the early reflections!) With the Rear Right delay being the longest, send the rear left delay return to sends #1 (pre-fade). This regenerates the longest delay through regeneration (spin), creating more delays that are longer but at lower levels with less high frequency content.
These longer delays are low enough in level that they dont generate dimension as a component of early reflections, but rather contribute in enhancing the richness of the reverb. In a real life situation, the early reflections coming from the walls continue to bounce from other walls to create dimension and eventually develop into highly diffused reverb. As the delays regenerate they will continue to lower high frequency content due to the equalizers inserted over the delay channel returns. If the engineer wants to further minimize the high frequency content regeneration in the delays, he can add another Eq on Delay send #1 on the rear right delay channel return.
With the slight difference in high frequency content and amplitude differences between the front delays and the rear delays, a realistic sense of distance and dimension is established.
This model for the B position for creating one fixed listening location will be effective if the listener wishes to hear all the instruments at the same distance and with similar sense of dimension in identical sounding environments.
Except this is not an effective strategy for all instruments!
The engineer should employ in a surround sound mix, a strategy to design different mix templates for hearing various instruments and vocals with different perceptions of distance and sense of dimension for the listener. The engineer can select the type of reflective surfaces (EQ on delays) and how large the environment is, indicated by the delay times and length and EQ of the reverb (RT-60).
In a pop-rock song, a valuable mixing strategy would have the listener hear: 1) the lead vocals as if he were sitting in the A position, 2) the guitar and piano situated at the B listening position and 3) the drummer performing from the C listening position. Because the Bass instrument possess low frequency content, creating dimension is challenging for two reasons: 1) bass frequencies are hard to locate due to the fact that they are omnidirectional and 2) bass frequency localization will result in rendering the mix very indistinct in the low frequency range. However if the bass were performing as a rhythmic element in the production, then creating localization in the 1khz-2.5khz with appropriate Eq and compression would effectively work.
If you physically moved the listening position a few meters further back from the location Bs center position, the amplitude of the direct sound will decrease in comparison to the amplitude of the reflections and reverb. As the listener moves further away from the sound source, the amplitude differences of sounds arriving to the listener via the direct path, early reflections and reverb decrease. In an extreme example, if a listener stood at the very rear wall of a concert hall, the amplitude of the direct path, reflections, and reverb would be extremely close together, creating the illusion that the listener would be at a substantial distance from the originating sound source and in a highly reflective environment.
All reverb will reach the B listening position later than 30msec. When music (audio) is sent from all 4 delay returns, the pre-delay will be zero or slightly later.
If reverb is sent directly from any music channels without sends to the delays, the pre- delay can be no earlier than 30 msec. The pre-delay should be marginally longer than 30msec to possibly 35msec to create a truthful reverb environment. It is absolutely impossible for the reverb to reach the listening position sooner than the first early reflection (30msec).
Reverberation is indicative of the size of the environment and how reflective the wall surfaces are. If the mix engineer wanted to create an environment where all of the walls are further away from the B listening position, than he will have to shift all the delay times (early reflections) later and likewise the pre-delay for the reverb. The pre-delay for the reverb sends from the 4-delay channel returns still remains at 0msec.
If the walls are composed of concrete and glass then the reverb (RT-60) will be bright sounding. For that type of hall at least a 6khz roll off is required in the reverb settings. Since the walls are highly reflective the decay time could be anywhere between 2.0sec- 2.5sec. It very much depends on the mixers sound aesthetics. Remember that the mixing engineer will have to still be aware of dense instrumentalisation and various tempos. The quicker the tempo with only 4-5 instruments will allow for a reverb decay time between 2.0sec-2.5sec and possibly longer with less instruments. If the production is complex with a quick tempo then a decay time between 1.5sec-2sec should work effectively. The mixing engineer should always make sure that there is clarity with clean harmonic distinction in creating dimension. If clarity is sacrificed and the mix is harmonically messy, it will sound like a piano player making quick chord changes with his foot permanently on the sustain pedal.
If the walls are composed of wood and fabric then the reverb will be duller however warmer sounding. A roll off frequency set between 2.5khz and 3.5khz is a good range to work within. As mentioned above, decay times should be base on aesthetics, density of the music production and tempos. Most classical and jazz mixing engineers strive for a very warm and highly diffused sounding reverb. Rock engineers with their desire for plenty of midrange prefer bright sounding shorter reverb times.
When adding surround sound reverb to the mix make sure there is no or very little reverb going to the discrete center channel and sub.
The A Position
NB: The A position will be represented by using the Lead Vocal as the original sound source.
The A position is located between 2-3 meters from the sound source (lead vocal). If the listener moves forward to the A position from the B position, the amplitudes and high frequency content of the direct sound, early reflections and reverb will be different, since the distance between the listener to the lead vocal is now shorter. There will be no slight drop above the 12khz as is in the B position. If anything, the mix engineer can take liberty and even increase the frequency content above 12khz a couple of db for it will create the impression of intimacy between the vocalist and the listener. How much of an increase is an aesthetic decision by the engineer.
For all intents and purposes, the early reflections do not exists and dont play a role in creating dimension since the distance between lead vocal and listening position is extremely close for the listener to perceive any effect from early reflections.
The reverb is the only other element besides the direct path sound contributing to the overall sound experience. It still only makes up 15% because the increase in direct path sound is performing with the largest amplitude in the A listening position. What is different about the reverb is it will be perceived as highly diffused with less high frequency content than the reverb in the B position. It will also be sensed as an overall longer sounding event than the B position. The reason for this is that the pre-delay on the reverb send of the A position is in between 80msec-120msec, which is longer than the pre-delay setting in B position, so the time difference between the onset of the direct path sound to the end of the decay time is longer because of the extended pre-delay time setting.
Creating Dimension in the A Position
Amplitudes
Direct Path Sound = 85% Early Reflections = 0% Reverberation =15%
Early Reflection-Delay Times
Non-Applicable
Surround Sound Reverb
- Decay Time = 2.0sec-3.0sec
- High Frequency Roll Off =2.5khz-3khz
- Roll off all frequencies below 100hz (6db/octave) Pre-Delay = 80msec-120msec
For moderate tempos assign a reverb time between 2.0sec-2.5sec. Reverb time length should be set in regards to the musical density in the song and its tempo. The length of the decay time is also an aesthetic choice by the mix engineer.
When reverb is sent directly from instruments to the same reverb being used for the lead vocal, then the pre-delay has to be longer than 80msec.
(It is impossible to hear reverb before the early reflections!)
An Option for the engineer to enhance a lead vocal or soloists reverb that is used in the A position, is to create a delay that is rhythmically linked to the tempo, such as an eight note or quarter note delay with some regeneration (delay feedback). One option is to add a small amount of delay return directly to the mix and send the delay and its regeneration to the same reverb being used for a lead vocal or soloist. If the engineer likes the additional rhythmic delay in the mix then he should take liberty in making the delay stereo instead of mono. If the tempo were, 120 bpm an eighth note delay would be 250msec. This would only be a mono return and might sound like a slap back effect if mixed in loudly, which is not the goal of creating an effective reverb effect. Instead of a mono delay at 250msec, instead create a stereo delay with the left return set to 240msec and the right return set to 260msec (or vice versa). As previously stated the delays have to be at least 15msec apart to avoid imaging problems. Remember to remove some of the high frequency content and also de-ess the send. This option has nothing to do with creating dimension but is used to enhance the essence of the reverb sound. The goal here is to extend the melodic idea contained in the original vocal sound or solo so that the melody sounds more appealing to the listener.
The basic idea of the hearing a performance in the A listening position is to situate lead vocals and solos in a mix to create presence and ambience. It additionally enhances the impression of a singer or soloist standing very close in front of you in a beautiful intimate sounding environment.
Creating Dimension in the C Position
The C listening position is the furthest from the sound source. The levels from the direct sound path, early reflections and reverb are much closer together in amplitude and high frequency content than the A amp; B positions. The early reflections and the original sound arrive later and are closer together because the entire sound experience has to travel further for the C position than in the A amp; B positions. Because theses time differences are closer together in value, the perception suggests that the listener is located at an extensive distance from the originating sound source and in an advantageous reflective environment. You will notice that the delay times of the 4 early reflections are all the shortest of all the listening positions. At this point it is imperative to remind you that the set delay times (early reflections) are referenced to the time difference between the arrival of sound from the direct path source and arrival of sound from the early reflections.
Amplitudes
Direct Path Sound = 55% Early Reflections = 25% Reverb (RT-60) = 20%
Early Reflections-Delay Times
- Front Left Delay = 15msec-Send #1
- Front Right Delay = 30msec-Send #2
- Rear Left Delay = 40msec-Send #3
- Rear Right Delay = 55msec-Send #4
Assign all 4 delay returns equally to post fade sends to Surround Sound Reverb
Equalization- Roll Off Point of High Frequency Content
- Front Delays Return channels = 6db/octave roll off @ 6khz
- Rear Delays Return channels = 6db/octave roll off @ 4khz
Delay Regeneration
- Delay return Channel #4 (55msec) #8212; assign pre-fade to sends #1 thru #4
- Allow for more regeneration than the B position setting, by sending more signal through the pre-fade send from delay return channel #4
Surround Sound Reverb
- Decay Time = 2.0sec-2.5sec
- High Frequency Roll off = 7khz
- Roll off all frequencies below 100hz (6db/octave)
A Mixture of Listening Positions
The various ideas and objectives for mixing in surround sound are to create distance and a sense of dimension in an enclosed environment with a choice of innumerable listening experiences perceived from various locations.
If the engineer wanted to mix the music of an orchestra in surround sound he would most likely use the B position and set all the required mics at predetermined levels. If the engineer feels like the original recording environment was too dead sounding because of a short reverb time in the recording studio or concert hall (RT-60), then he could add artificial surround sound reverb to allow for extending the reverb decay time. If the engineer feels the tempo of the music recording is so quick that it was causing harmonic and rhythmic confusion, then he could favour the Decca Tree mics and the Flank mics more than the ambient mics.
He might also have to pan the left and right flank mics towards the rear channels while retaining their stereo image. This would assist in maintaining consistent amplitude and stereo imaging of the orchestra layout in the mix yet there would be a minor drop in amplitude from lowering the levels of the ambient mics that would need to be compensated for. The engineer could also experiment with moving the left and rear ambient mics waveforms together but closer to the waveforms of the flank mics and Decca Tree mics in a Pro Tools session. This movement of the waveforms would have to be in milliseconds and would be based on the listening aesthetics of the engineer for it might compromise a realistic sense of dimension for a surround sound environment.
If a solo instrument such as a cello or flute or any other instrument with dynamic limitations, inevitably there would be a need to raise the instruments amplitude in key sections of the performance. The problem with raising the level of the close-spot mic is that the sense of dimension begins to fragment and falls apart. Raising a close mic level will establish too much of a dry sound and no longer will the solo instrument sound like it is performing in the matching acoustic environment as the orchestra. The solo instrument will sound like it is being perceived from the A position with the orchestra being perceived from the B position. To rectify this situation, the engineer needs to add early reflections (delays) and reverb to the solo. The early reflections (delays) and surround sound reverb need to emulate a matching type of environment of the orchestral sound. By judiciously evaluating the sound of the ambient mics from the recording, the engineer will have a source reference to match the additional delays and reverb to.
If the piece of music is a Concerto, there are three combinations of sound; 1) Orchestra only, 2) Solo instrument only and 3) Orchestra and solo instrument together. When the solo instruments dynamic range is limited, like a cello then there will be major amplitude changes between when its only the cello performing and when the entire orchestra is performing. Even an instrument like the grand piano can easily be drowned out when the orchestra is performing with extreme dynamics.
These days the size of most orchestras are larger than they were 200 years ago. In the 17th and 18th centuries the orchestra was designated as Chamber and numbered between 40- 50 musicians. In the 20th century it doubled to close to 100 musicians and designated as a philharmonic or symphony orchestra. Therefore a lot of concerto compositions by the most notable composers such as Bach, Beethoven and Mozart were written for the only orchestras size that was known to them at that time, which was under 50 musicians. The solo instrument had a good chance of being heard clearly when performing with that size of an orchestra. These days with larger orchestras, there can be amplitude battles between the soloist and the orchestra. I also believe there are additional mixing challenges today, 1) the obvious noticeable differences in amplitude between the various movements within the entire concerto and 2) The lack of listening position perspectives between the movements.
There are solutions to solve the above dilemmas that the mix engineer can easily utilize. When a soloist is performing, the engineer can easily raise the amplitude of the close mic channel and add delays (early reflections) and reverb (with pre-delay) to assist the solo in matching a sound that emulates the environment of the original recording. The engineer can also take liberties in raising the overall amplitude of the solo instrument so there are no drastic dynamic changes that might be undesirable for the listener.
What I like to do is take an additional liberty in having the solo instrument appear to being heard from the A position instead of the B position. My motive for this is that when an instrument like a cello is performing solo in a concerto, the interpretation of the music lends itself to being more intimate and emotional which can only be accomplished by locating the cello in the A position. What I do not appreciate is when the opening movement of a concerto is full orchestra heard in its ideal B position, is the transition into the solo cello movement being heard from the same B position. When this occurs, I feel the need to pull the sound of the cello closer to me with a slight increase in amplitude and Eq presence and intimate reverb. In a hypothetical situation I would sit in the first row of the balcony of the concert hall when the full orchestra is performing and then move to the floor, 5 rows back from the stage when the cello is performing solo. I would obviously have to tell the conductor to stop the performance between movements for I would need the extra time to switch seats. But this idea of stopping and switching seats is ridiculous, but a change in amplitude and sense of dimension can effortlessly be accomplished in the mix process.
To achieve the best sense of dimension in surround sound is to assign different instruments and vocals to be heard from the 3 listening positions. The engineer cannot expect to assign all musical elements to one position and have the listener keep moving forward and backwards in the theater or at home to appreciate different senses of dimension. The strategy in mixing is having the listener stationary in one location, a sweet spot as they say, and apply to the mix the techniques of using delays (early reflections), reverb, different EQ and different levels for all of the elements that will contribute to generating a sense of dimension.
When I work on orchestral recordings with soloists and I alter the sense of dimension to meet all my aesthetic needs that I feel the listener will also enjoy. When I was mixing a film soundtrack in surround sound that featured Andrea Bocelli with the Berlin Philharmonic, I took plenty of liberties in the mixing process. I placed the orchestra in the B position and Andrea in the A position. When the listener is hearing the surround sound mix in the cinema or home theater they will perceive Andrea positioned 3 meters in front of them with the orchestra positioned 10 meters further behind. The vocal will have a long pre-delay (100msec) on the reverb send (de-essed), no delays (early reflections), equalized for presence and the reverb EQ will be rolled off at 2.5khz. The orchestra will have a shorter pre-delay (40msec), early reflections, no EQ, and the reverb EQ will be rolled off at 3khz.
If I am mixing a pop song, I will enlist the following process: The A position will contain the lead vocal and guitar solo. The vocal and solo will have a long pre-delay (80msec) on the reverb send (de-essed), no delays (early reflections), equalized for presence and the reverb EQ will be rolled off at 3.0khz.
The B position will contain the piano and rhythm guitar. They reverb pre-delay will be (35msec), early reflections (LF-30msec, RF-45msec, RL-50msec, RR-65msec), and the reverb EQ will be rolled off at 4khz.
The C position will contain drums. The reverb pre-delay will be 20msec, early reflections (LF-15msec, RF-30msec, RL-40msec, RR-55msec-all with generous regeneration), and the reverb EQ rolled off at 5khz.
As you can see all the settings are different for the 3 listening positions.
Alternate Position #1
The only way to hear all three elements of the sound evenly would be to stand in the lobby of the concert hall with the doors open to the hall. The arrival of the direct sound path, early reflections and reverb would all arrive to the listening position at the same time with the same amplitude. This would basically be the C listening position with the direct sound level 34%, the early reflections 33% and the reverb at 33%. This strategy would be useful for a creative idea in making an instrument/vocal sound like it is originating at an extreme distance from a highly reflective environment. It could also be used in manufacturing a sound effect with similar dimension.
Creative Placement
In attempting to create a realistic sense of surround sound dimension, one should also consider redefining the boundaries of a fixed listening environment. If a stereo sound source were to be perceived as only coming from behind the listener, the engineer would pan the stereo source 2 early reflections and stereo reverb to the rear left channel and the rear right channel. By manipulating the factors that contribute to creating dimension, the engineer can generate different depths of sound for an original stereo sound. This can also be used to create stereo localization on left and right sides of the surround sound mix. Instead of using the 2 rear channels, the engineer can use the left front and the left rear or the right front and the right rear. This will also work with mono localization at the mid-left or mid-right points exactly between the front and back channels. The effect is to generate discrete localization with dimension exclusively coming from the rear, left or right.
Conclusion
Mixing in surround sound is very challenging and exceptionally rewarding. Once rudimentary and essential laws of sound are understood, entirely alongside effective strategies for creating a sense of distance and dimension, the engineers mixing ability and potential will have enormous opportunity to be celebrated and realized in the world of surround sound!